
PDF/UA examples, Accessible HTML
SpringMT 2023 PDF/UA and HTML – Accessible
Ross Moore
November 2023
SpringMT-2023: Management Track Assessments Spring 2023
- •
PDF/UA: a pre-publication version of SpringMT-2023: PDF version ;
- •
- •
PDF/UA: updated for DPUB-ARIA and later validators, 23 January 2024: PDF version ;
- •
- •
Some features of these PDF and HTML documents were discussed at the TUG 2023 meeting, in Ross Moore’s presentation video.
The method of production follows these steps.
- 1.
First LaTeX source is processed to build a Tagged PDF valid for the PDF/UA-1 format.
- 2.
The resulting PDF is derived into an HTML version using ngPDF .
- 3.
The HTML page, and any images, is then downloaded and copied to this location.
- 4.
Some post-processing with
sedcommands is done on the HTML to remove some incorrect structures, invalid attributes, and the ‘- ’ remnants of hyphenation within the PDF.
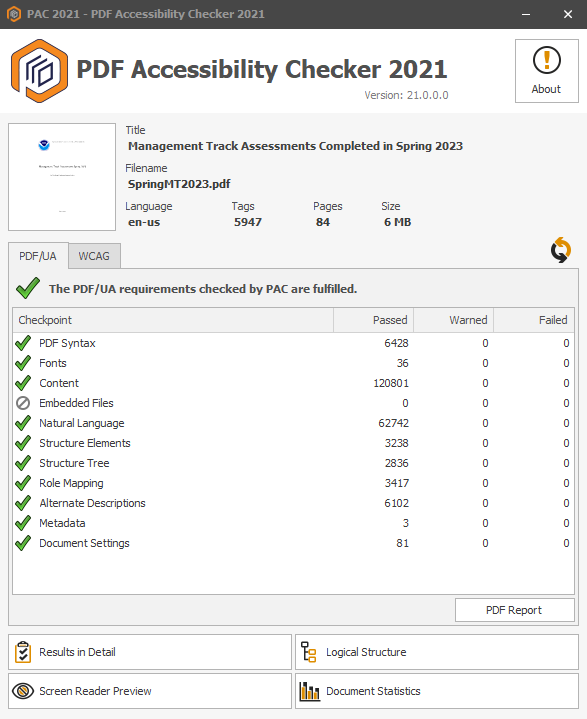
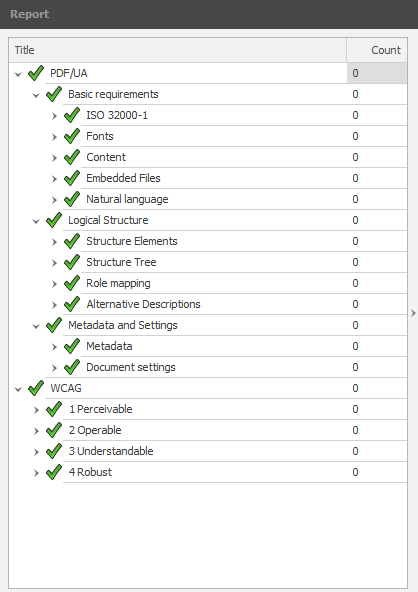
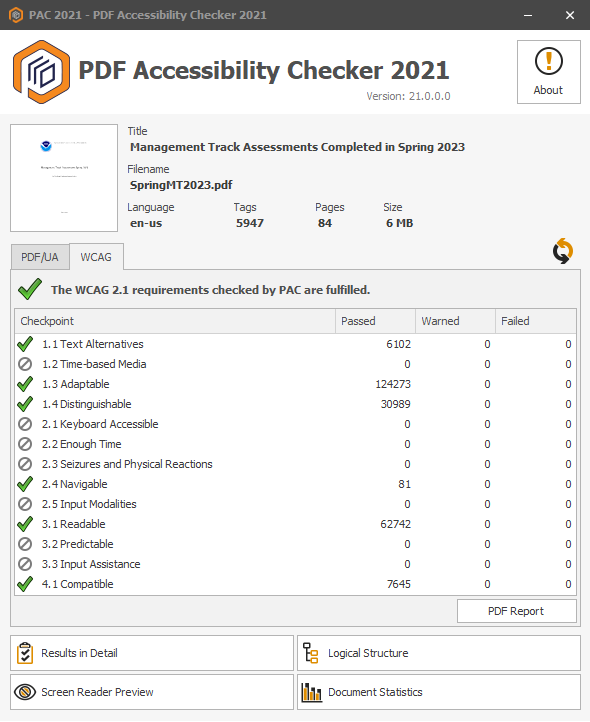
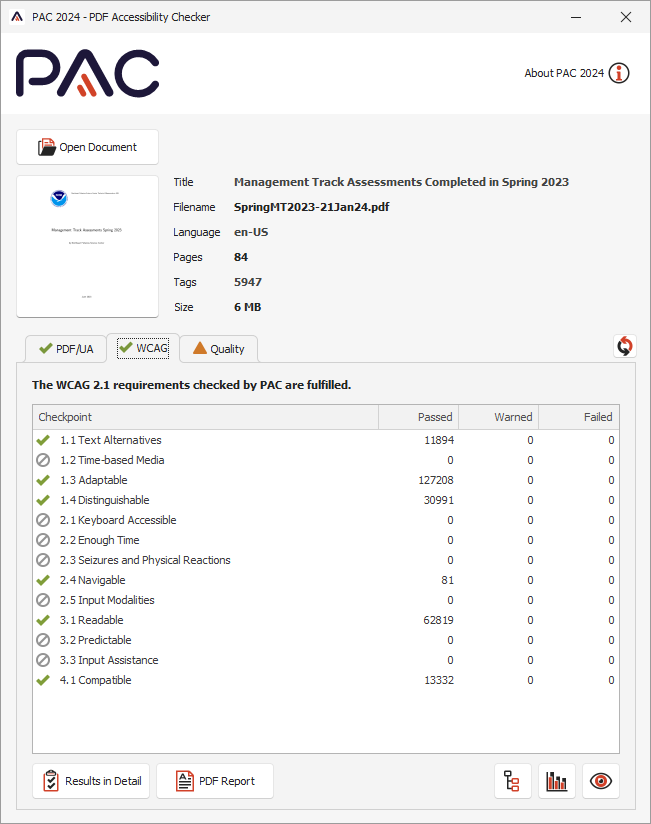
Validation for PDF/UA and WCAG 2.0 using PAC 2021
The PAC 2021 (PDF Accessibility Checker) is very good software for checking the validity of a tagged PDF document for conformance with the PDF/UA-1 standard. Unlike other validators (veraPDF, Adobe Acrobat Pro's Preflight Tool, and BFO-pdf) it also pays attention to the ‘containment rules’ concerning how common structure elements can occur as children of other such elements. Furthermore, it has extra heuristics for checking some aspects of WCAG recommendations, beyond what is built-in to PDF/UA format itself. An update PAC 2024 is due for release in early 2024; thanks to Thomas Schempp for allowing early access to a pre-release version.
The results for SpringMT2023.pdf, passing all applicable tests in PAC 2021, are summarised in the images shown here:
| PDF/UA tests by category … | … all categories … | … by WCAG 2.1 success criteria. |
|---|---|---|
 |
 |
 |
Other outputs from PAC 2021 and Acrobat Pro are as follows:
- See the Summary Report in PDF format.
- Screen Reader Preview: an emulation in HTML of how Assistive Technology might read aloud the PDF/UA document. This includes extra ‘spoken tags’ which briefly explain the structure;
e.g. ‘; Title ;’, ‘; start of section named ... ;’, etc. - Export from Acrobat Pro: Text (Accessible) plain-text version, including the ‘spoken tags’.
- Export from Acrobat Pro: XML 1.0 format includes Metadata, Bookmarks, etc.
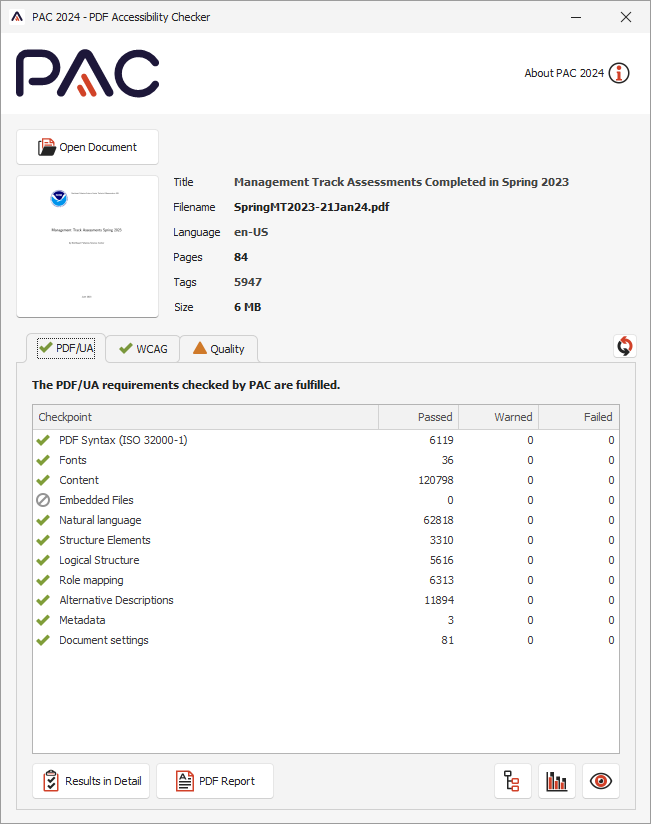
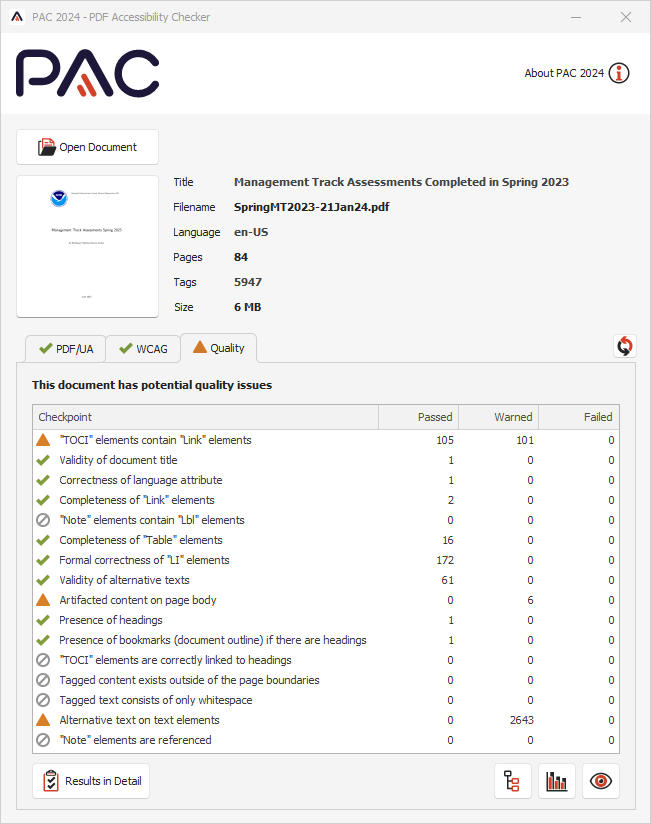
Validation for PDF/UA and WCAG 2.0 using PAC 2024
With PAC 2024 the results are similarly passing all test for PDF/UA and WCAG categories. There is a new ‘Quality’ category having additional tests. Some of these tests are designed primarily to help authors using particular PDF writing software (not LaTeX) avoid making common errors. However this results in flagging some constructions, as seen in the image at right below. Most are designed to give a better result when ‘Read Out Loud’ using Adobe's Acrobat and Reader.
The results for SpringMT2023.pdf, passing all applicable tests in PAC 2024, are summarised in the images shown here:
| PDF/UA tests by category … | … by WCAG 2.1 success criteria. | Quality |
|---|---|---|
 |
 |
 |
Click here for the 'Screen Reader Preview'. This includes the ‘spoken tags’ described above. Note however that many of the images have not been created correctly from the PDF; of 43 images, only 9 have captured the correct area on the PDF page. It needs to be remarked that the tests results summarised above are limited to sub-categories: 1.1.1, 1.3.1, 1.4.3, 2.4.2, 2.4.3, 3.1.1, 3.1.2 and 4.1.1 .
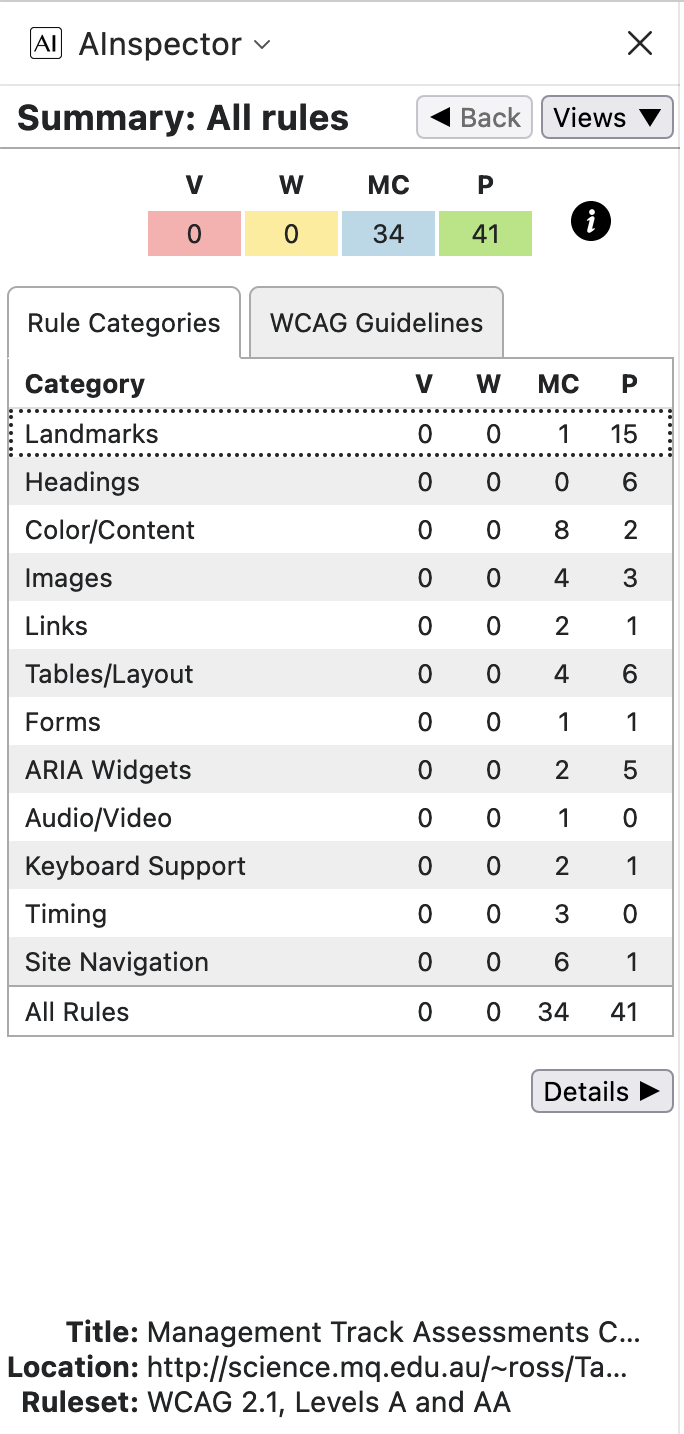
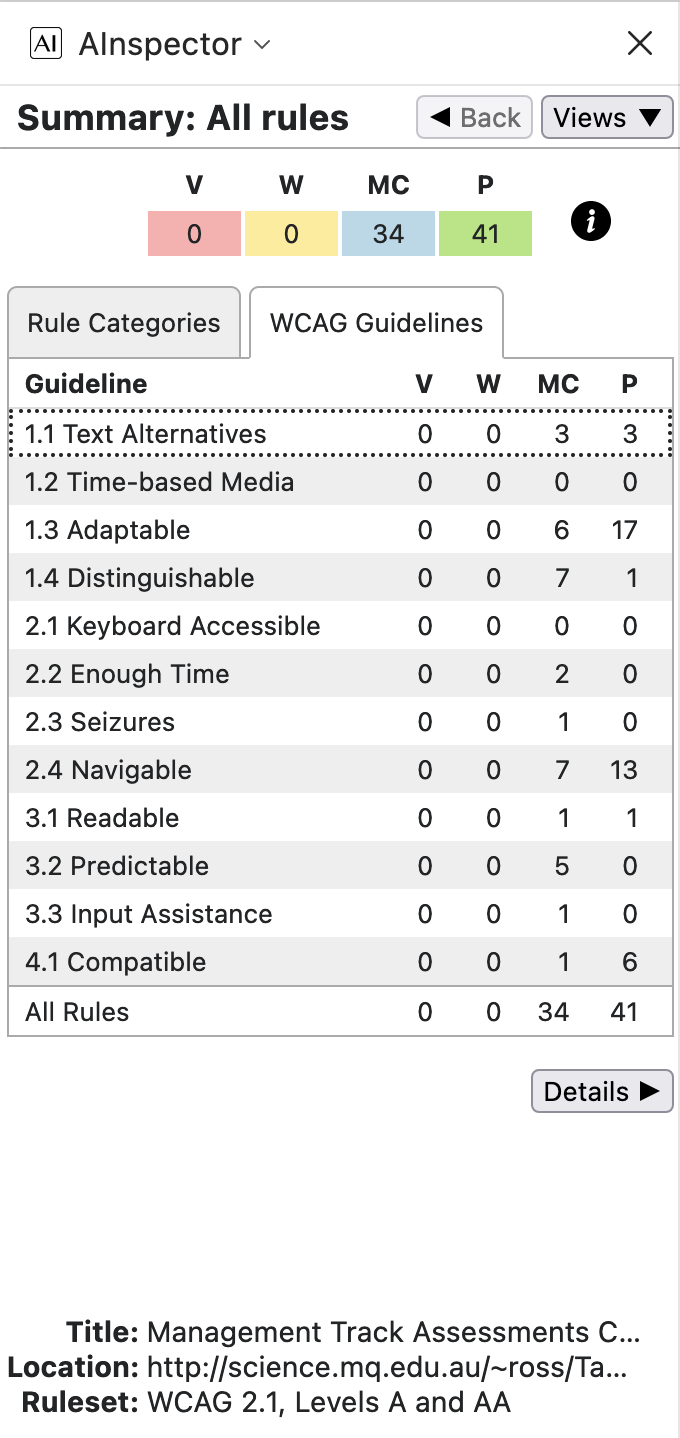
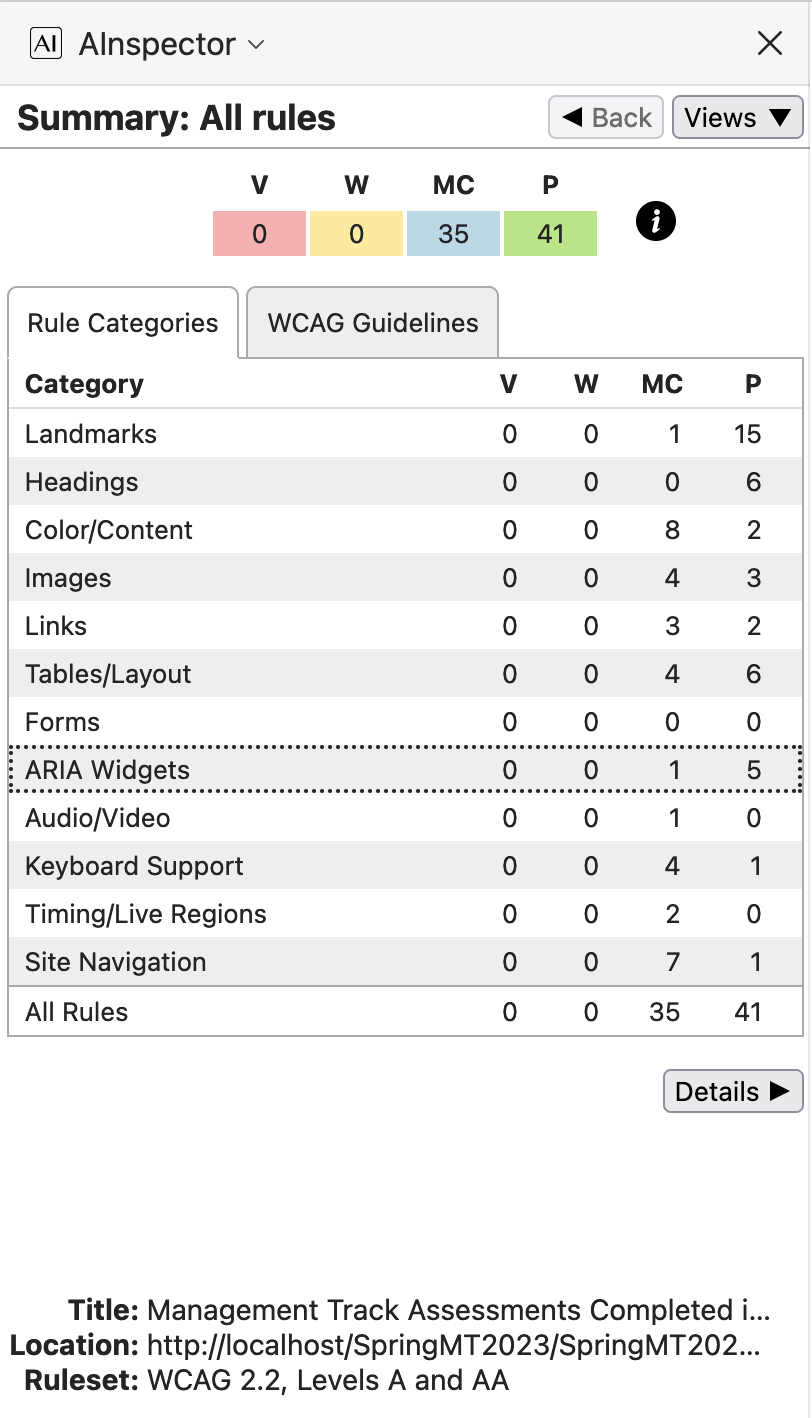
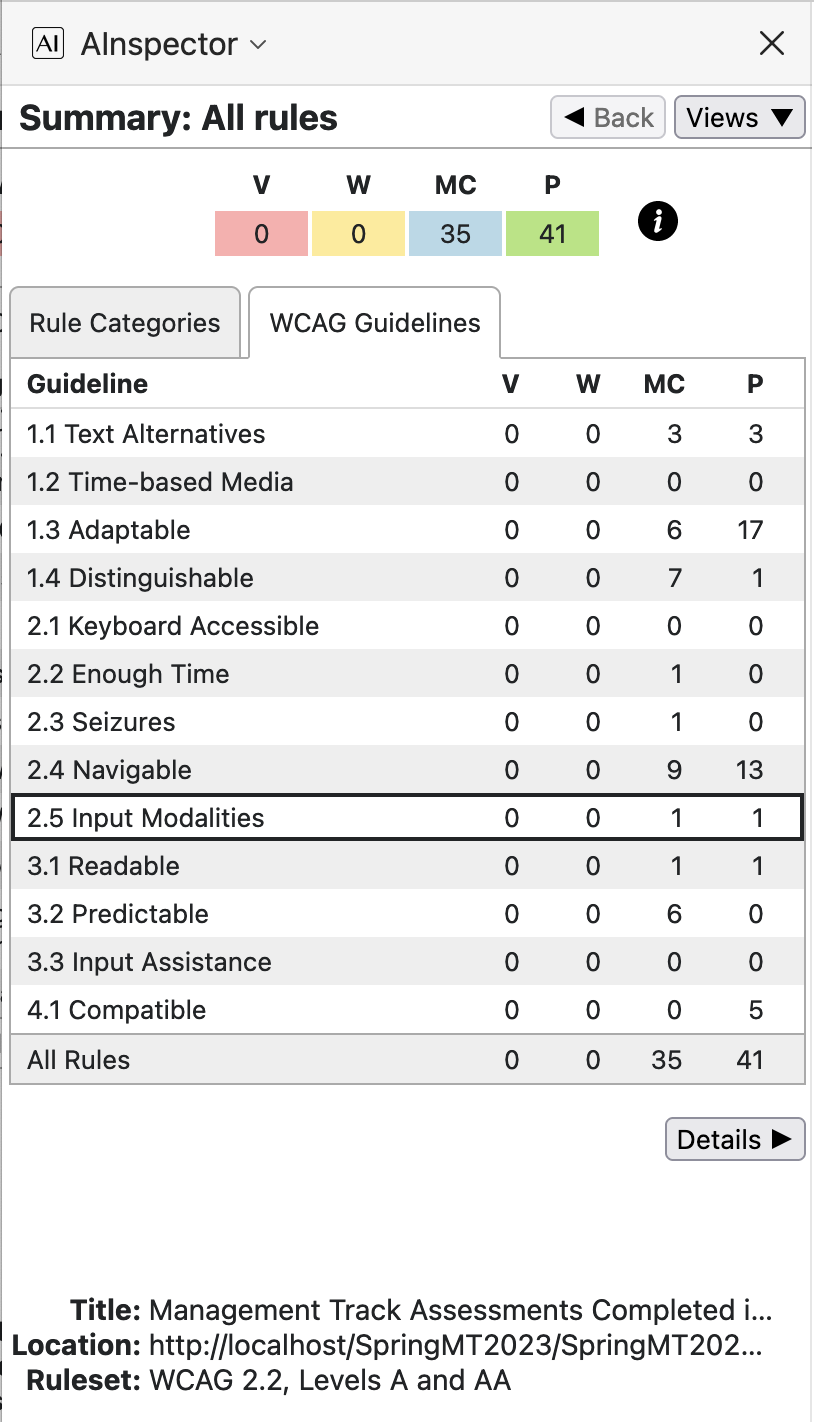
Accessibility: WCAG 2.1 and ARIA Success Criteria
The following images and explanatory notes indicate how WCAG and ARIA recommendations and requirements are handled. We use the AInspector for Firefox plug-in extension to the Firefox browser, to algorithmically check many aspects of these recommendations.
The results are summarised below, listed according to structural categories, and alternatively according to WCAG Success Criteria groupings. The table headings are V: violation, W: warning, MC: manual check, and P: pass.
|
|
Note that there are no violations and no warnings, with 34 possible issues requiring manual checking, some of which will be dealt with below. As well as the 41 rules which are algorithmically verified as Pass, there are 58 further rules or recommendations deemed to be not applicable, making up to 133 types of test in all. For instance, since there are no interactive Form fields in the document, then most checks under the ‘Forms’ category are deemed inapplicable; similarly for most under ‘Widgets/Scripts’ and most under ‘Audio/Video’ as well as a few in other categories. This is actually an over-count, as some tests may have some elements Pass while others may need further checking.
2024 updates: WCAG 2.2 and DPUB-ARIA considerations
With a string of updates, and the name changed to ‘AInspector for Firefox’, the validation software has improved. In particular the issue with table rows being treated as ’widgets’ has been fixed, so that redundant tests are no longer being performed. Below are shown the results for the more recent HTML created without using the DPUB-ARIA roles, since these are yet to be well supported in screen-reading software. Work is ongoing in AInspector, to recognise DPUB-ARIA roles at least as something for Manual Checking; when ready, revised results will be shown here.
|
|
The totals do not seem to have changed much; but no longer having any tests relevant to ‘Forms’, fewer for ‘ARIA Widgets’ and ‘Timing’. There are more tests under ‘Links’ and ‘Keyboard Support’. Also there are now 64 tests deemed N/A, for a total of 140 overall.
WCAG/ARIA Success Criteria details
Click on images below to jump to discussion of the relevant WCAG Success Criteria.
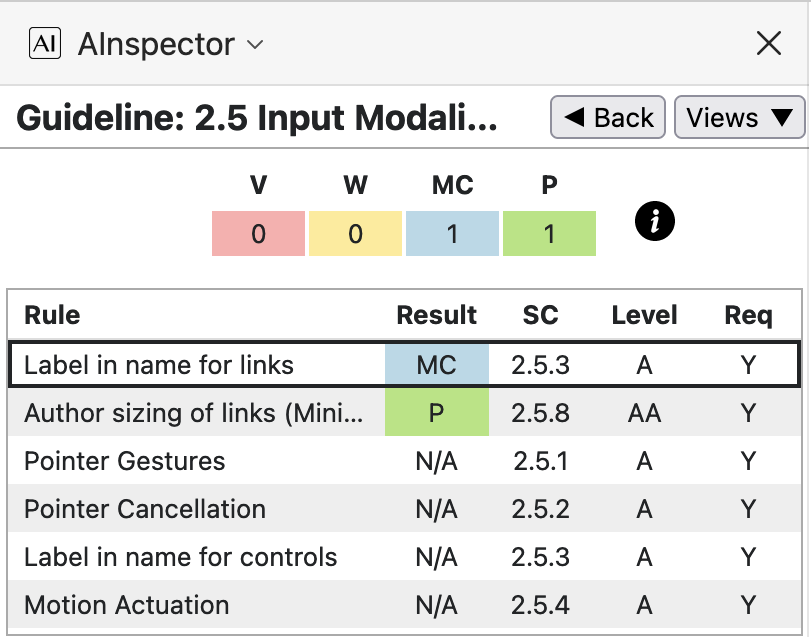
‘Accessible Name’ and ‘Accessible Description’
The ‘Accessible Name’ concept typically is used to construct a name for the target of a hyperlink, though it can be used also with other structures, such as lists and tables. This name should convey the purpose of the link; that is, indicate the type of information to be found if the link were to be followed. Assistive Technology (AT) should construct this name, and may present it in place of the anchor-text of the hyperlink.
The ‘Accessible Description’ typically gives a constructed summary of the information to be found at the target of the hyperlink.
It is also used to provide a description of non-textual material, such as an img, located
in a <caption>, or at some other location in the document.
The summary should be unique in the sense that links having the same ‘Accessible Description’ should have identical summary.
Assistive Technology (AT) should construct this summary, and have a means to present it to the user, as an alternative to switching
focus to elsewhere within the document to learn more specific information about what is to be found at the target of the hyperlink.
Comparison with PAC results
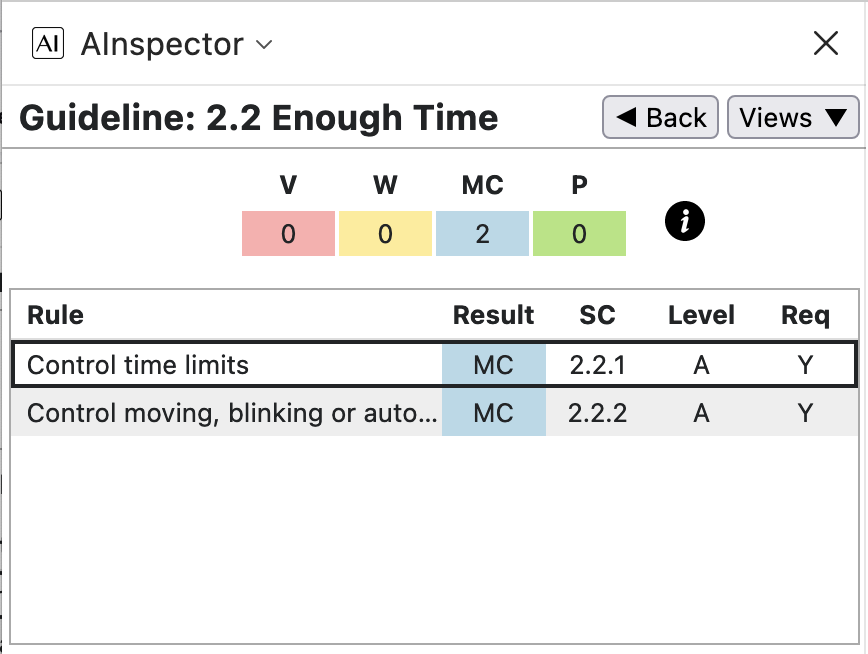
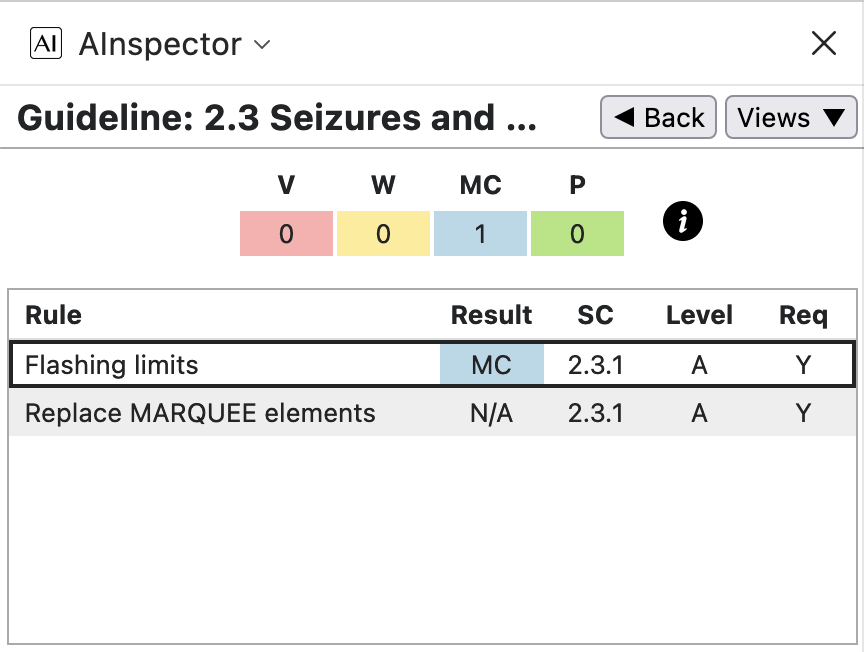
- Whereas PAC has no tests for 7 of the WCAG Guidelines — also known as Success Criteria (SC) — AInspector has Manual Checks under criteria: 2.2, 2.3, 3.2 and 3.3. These are for things that cannot be determined programmatically; such as content not automatically changing, images not flashing too rapidly, methods to avoid errors using form controls – of which there are none in either the PDF or HTML versions. While it is not possible to definitively claim a Pass for relevant structures, this can be inferred from a knowledge of the material being used to construct the PDF. For example, with all text and images known to be static, there can be no flashing or rapid change of content. Some tests under 2.5 can be determined programatically.
- Under SC 3.3, AInspector 2.99 treats each table row as if it were an interactive widget; e.g. in a grid of cells taking keyboard input. This is not the case for the static data tables in the PDF, nevertheless an associated Manual Check is stated as being relevant. This was reported as a bug in the AInspector software, which is now fixed in the v3.0 release.
- Under SC 3.2, AInspector states a need for Manual Checking related to consistency of structures and heading levels, etc. when moving between different pages of a website. With a single web-page produced from a single PDF document, such tests are effectively irrelevant. These tests would be relevant if the PDF had been used to derive a multi-page HTML website, so would correspond to consistent use of styles and structures within the PDF itself.
Instead of displaying just the gray ‘no go’ icon indicating that no tests are applicable, it would be perfectly reasonable for those Success Criteria to be discussed in the User Manual, or other documentation. There could be links to the relevant pages,
on which the issues are discussed. And there could be links to the places in the PDF where a Manual Check ought to be done.
* With the release of PAC 2024 in December 2023, the software now does produce links to websites that explain the test conducted.
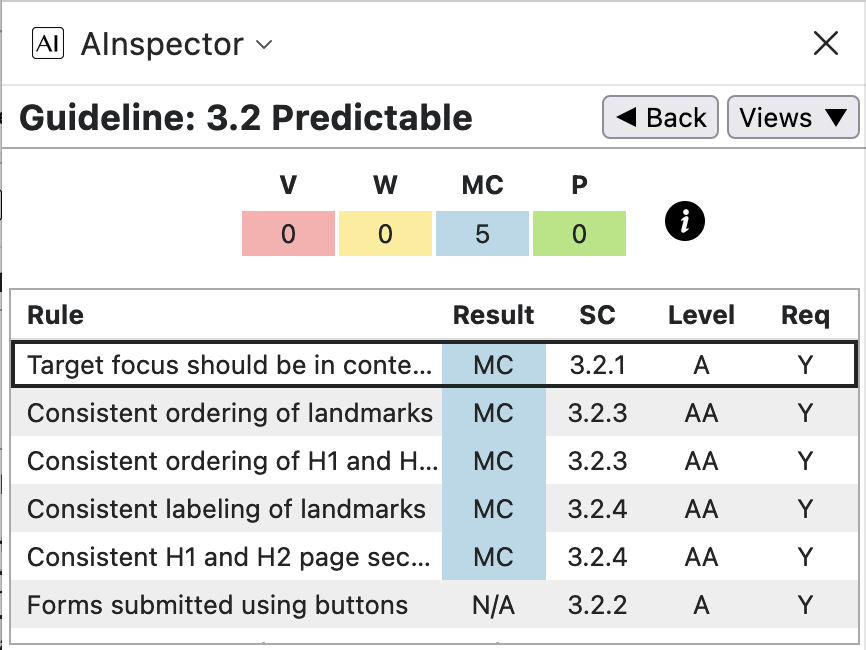
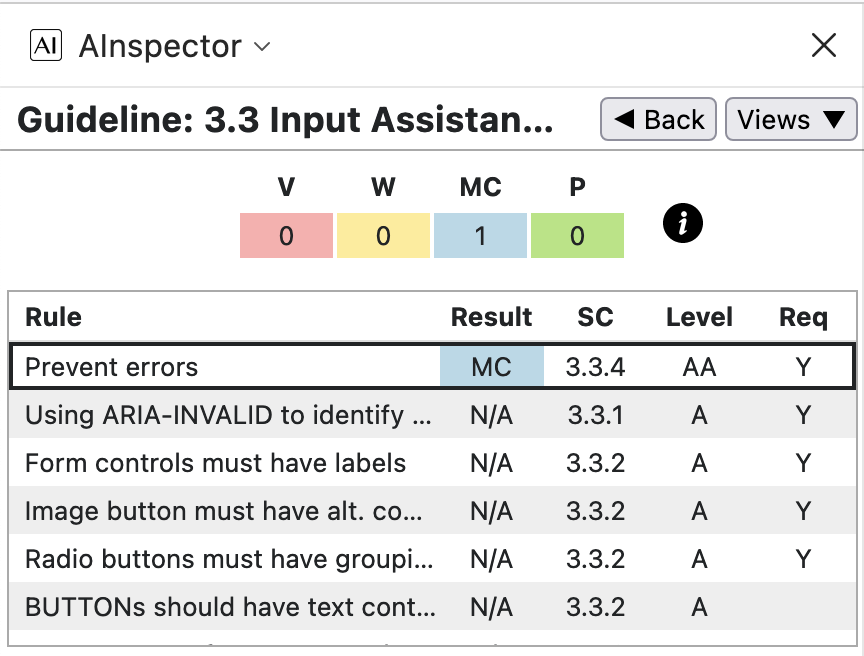
- In the 6 categories where automated checking is possible (1.1, 1.3, 1.4, 2.4, 3.1 and 4.1) AInspector recommends further Manual Checks beyond what is determined as Passing. In the following subsections, these are studied in some detail. Refer also to the Guideline images above.
In the following we give an image of the AInspector panel in the Firefox browser, focusing on a structural element to which the rule applies. Sometimes this is accompanied by an image from a PDF browser, showing how relevant structure and attributes are specified. In those cases where the rule is applicable to the document as a whole, there is no structural element to take focus.
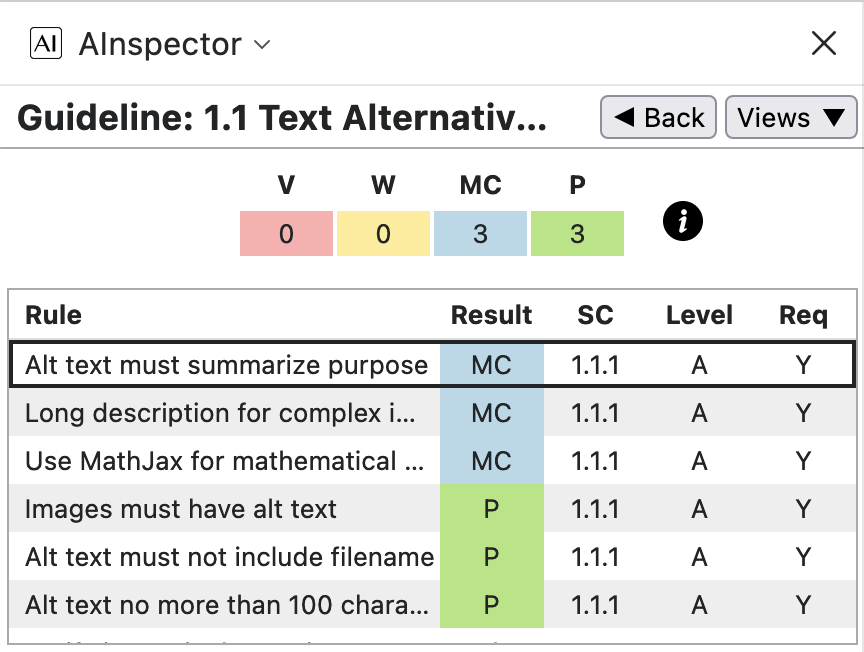
WCAG Guideline 1.1: Text Alternative
- 1.1.1 ‘Alt text must summarize purpose’
That all images have an
altattribute can be checked programmatically; as can that this is not just the filename of the image, and that it is no more than 100 characters. Not so easy to check is that this Alt-text is actually relevant to the image; but one would expect that ensuring this would be part of the editing and proofing for the PDF publication. In some PDF and HTML browsers this is easily checked by hovering the mouse over the image and reading what pops up.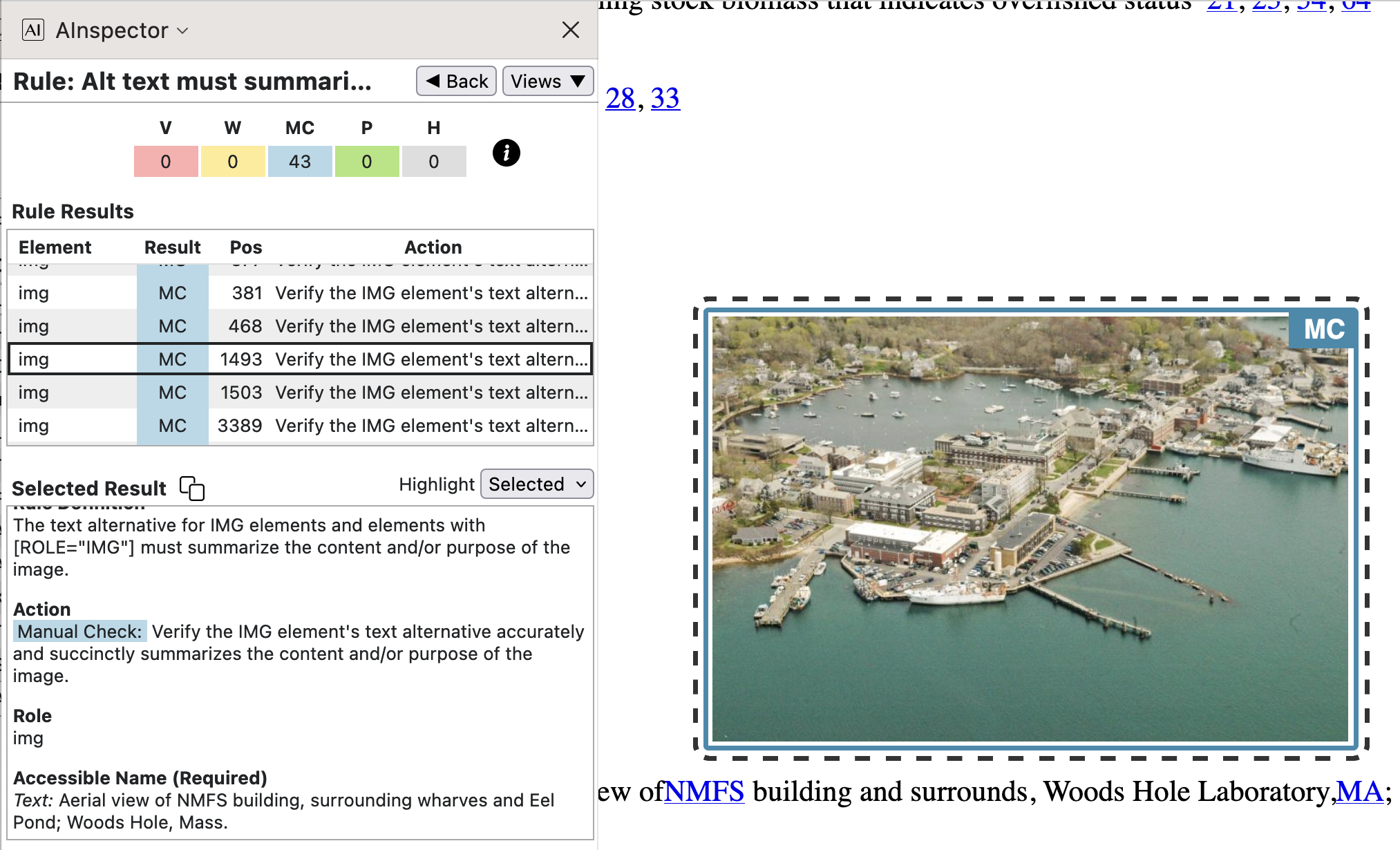
- 1.1.1 ‘Long description for complex images’
Accessibility and understanding can be further enhanced when the document contains a ‘long description’, being a reasonably brief summary of what is seen within the image, or explaining its relevance. This could be a caption, or some text appearing elsewhere in the document. If so, then a reference to this is an appropriate value for an
aria-describedbyattribute.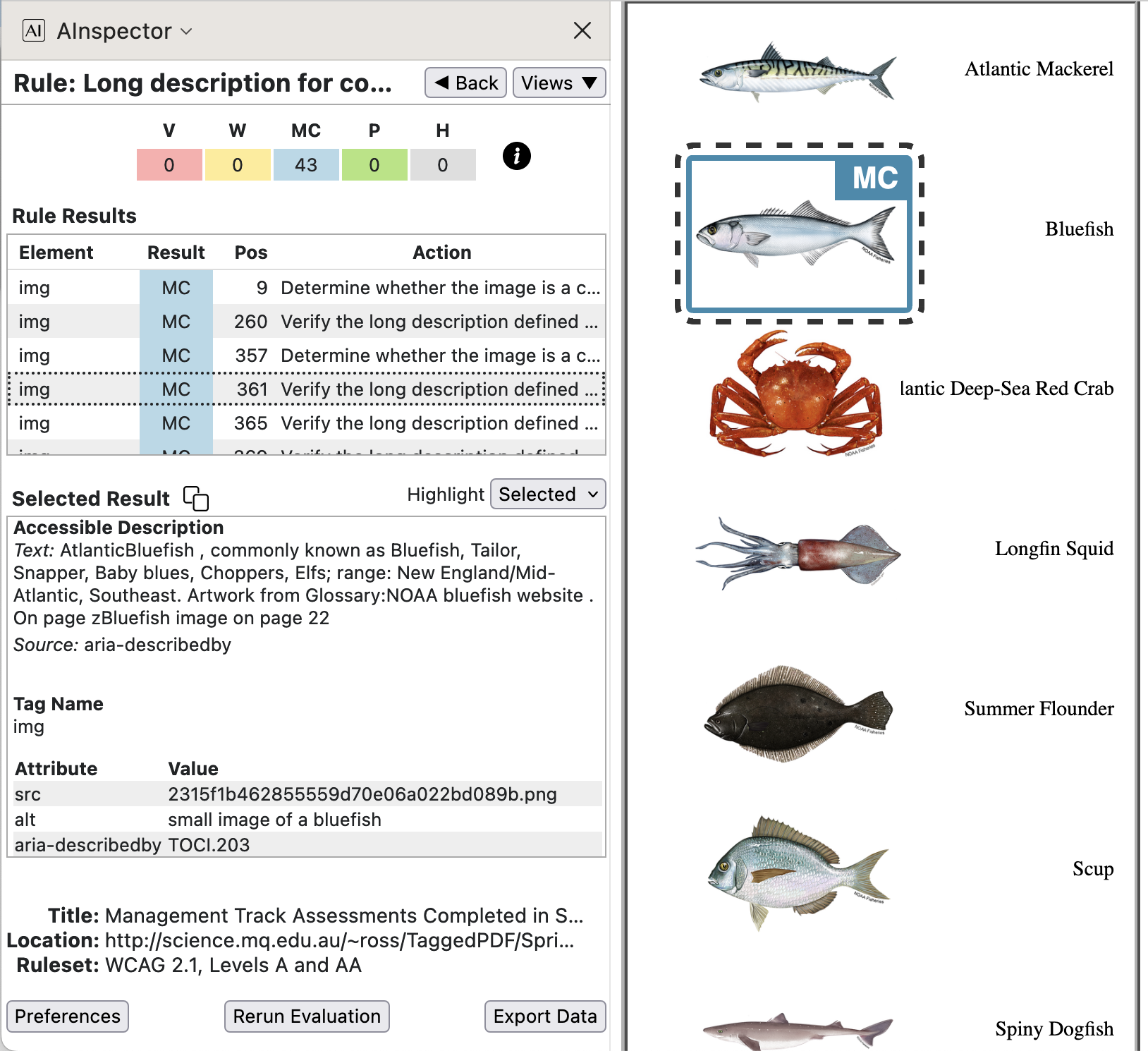
In the image above, we see the ‘long description’ which appears in the ‘Photo Gallery’ Glossary structure, concerning the Bluefish species. This occurs structurally under the identifier ‘TOCI.203’. The MC still requests to manually ‘Verify’ the relevance of the text found there. As this gallery also includes acknoeledgements of the source of the images, since January 2023 it is now also given the DPUB-ARIA role of
doc-credits; each listed item now has the accompanying required DPUB-ARIA role ofdoc-credit.When there is no such
aria-*attribute, the MC request is to ‘Determine whether … ’ there could be a reference to some relevant part of the document. For this PDF, there are reports for 5 of the 7 fish species. Those 5 have a ‘Photo Gallery’ entry, whereas the other 2 do not — the first and last of the small fish images. To confirm relevance it would be sufficient to understand how the chosen references are determined. In the example PDF the identified Glossary entries are for the same images being shown at a larger size within the Report sections for those fish species’ stocks.In practice it is much easier to ‘Verify that … ’ for some specific piece of text, than to ‘Determine whether … ’ something applicable exists within the document. So it is highly desirable to include a link to such a ‘long description’ whenever possible, using an
aria-describedbyreference. That has been done with this example PDF and its derivation into HTML.Here are some more examples for types of images used in the PDF and derived HTML.
- The NOAA logo serves also the purpose of being the clickable anchor of the ‘skip to Main’ link at the
beginning of the document.
This explains the final portion of the
alt-text, as seen in the image below.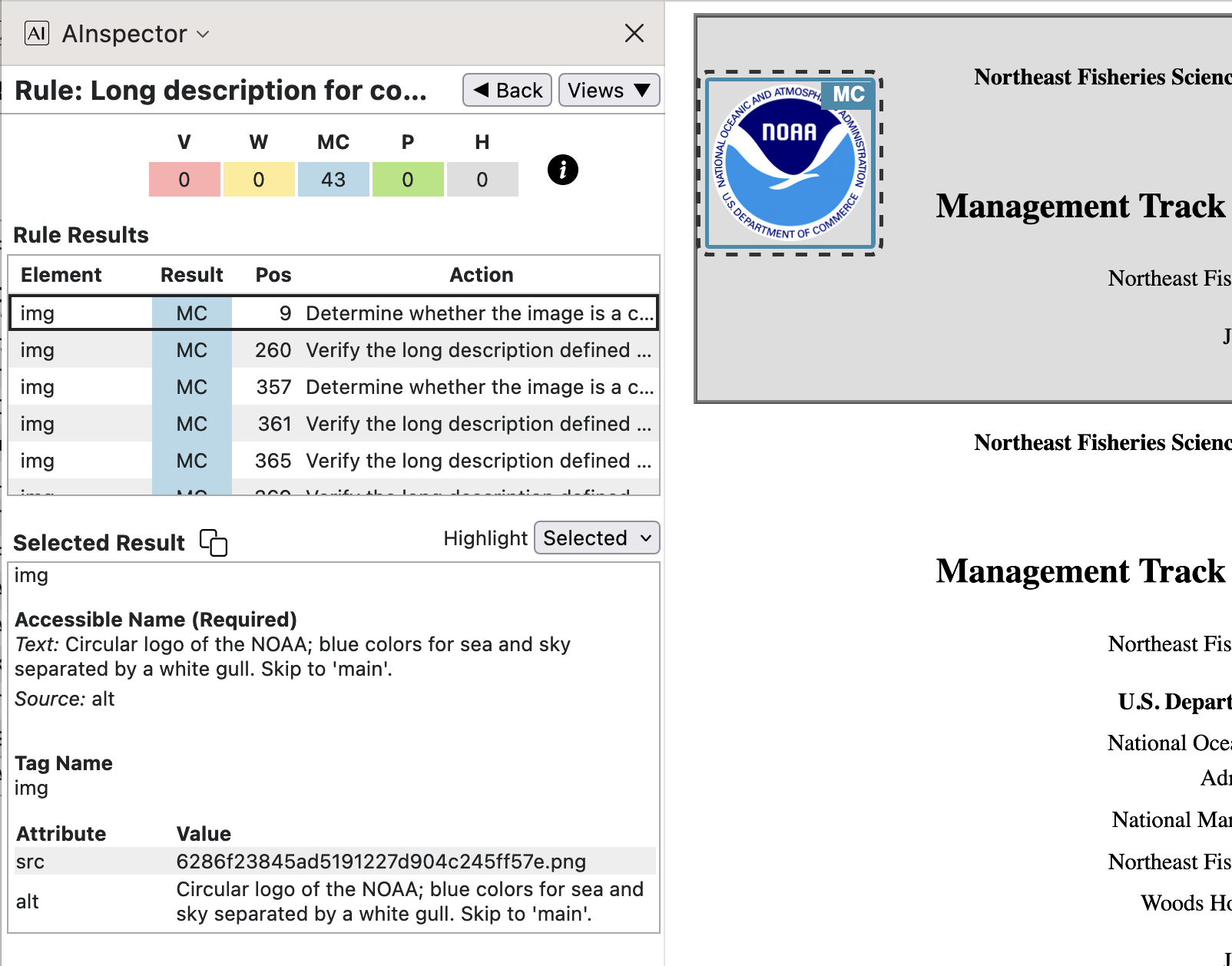
Details and history of the adoption of this logo can be found at the site ‘About the NOAA emblem and logo’. Using this as target for a
longdescattribute is deprecated in HTML-5, so we do not do so. If a design decision had been taken to include some of this explanation, on the inside of a cover-page say, then that would be an appropriate target for anaria-describedbyreference. - With line plots and other charts, there is a caption which follows. This is used as target for
aria-describedby.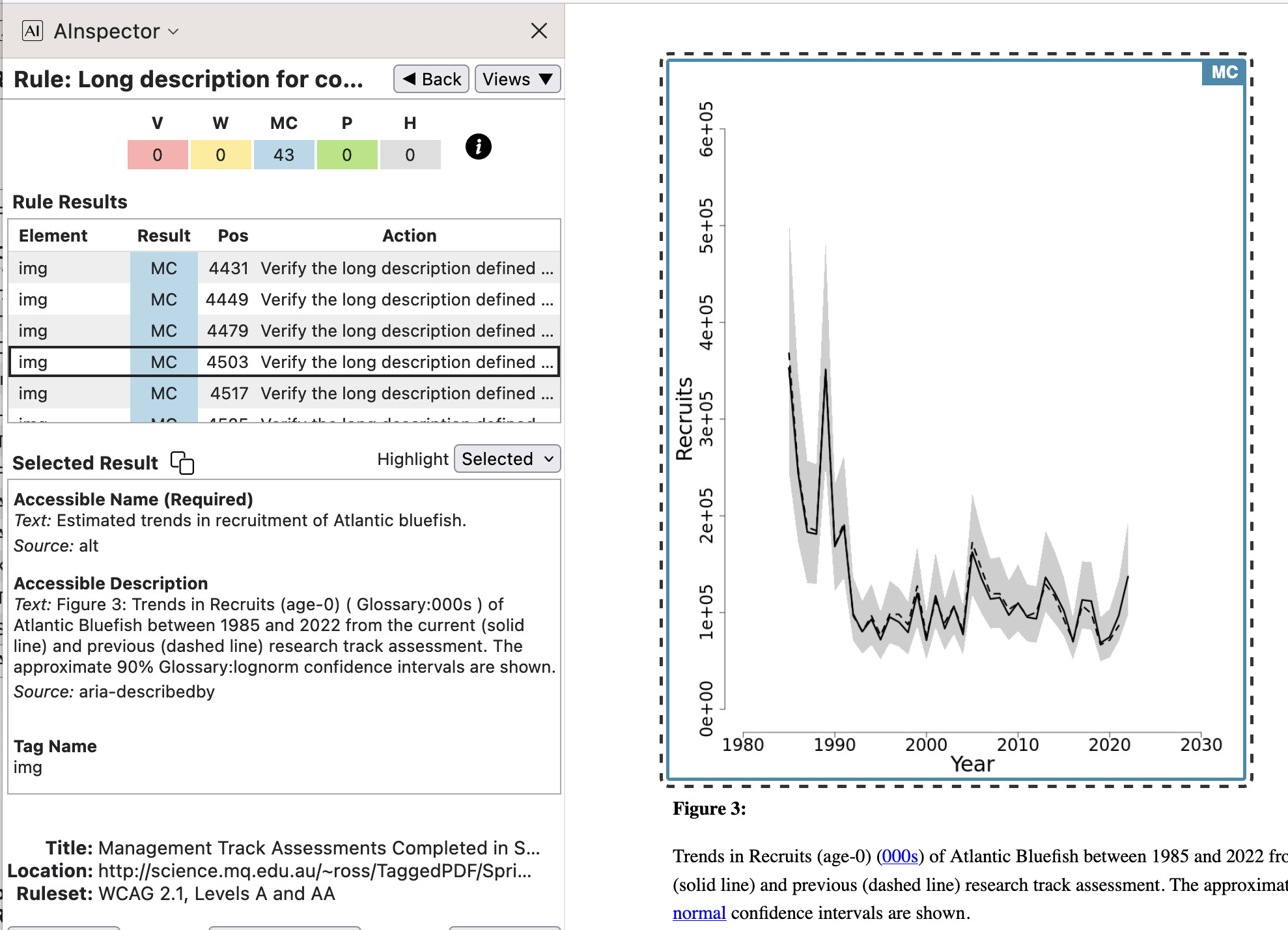
It is part of the usual editorial process to verify that there is a caption, that it is relevant, and its accuracy. Internal LaTeX coding ensures that it becomes the target text for a PDF attribute.
- Illustrative photos have an entry in the ‘Photo Gallery’ section, which is implemented as a Glossary.
The text found there, including a page-number link, is used as the target for
aria-describedby.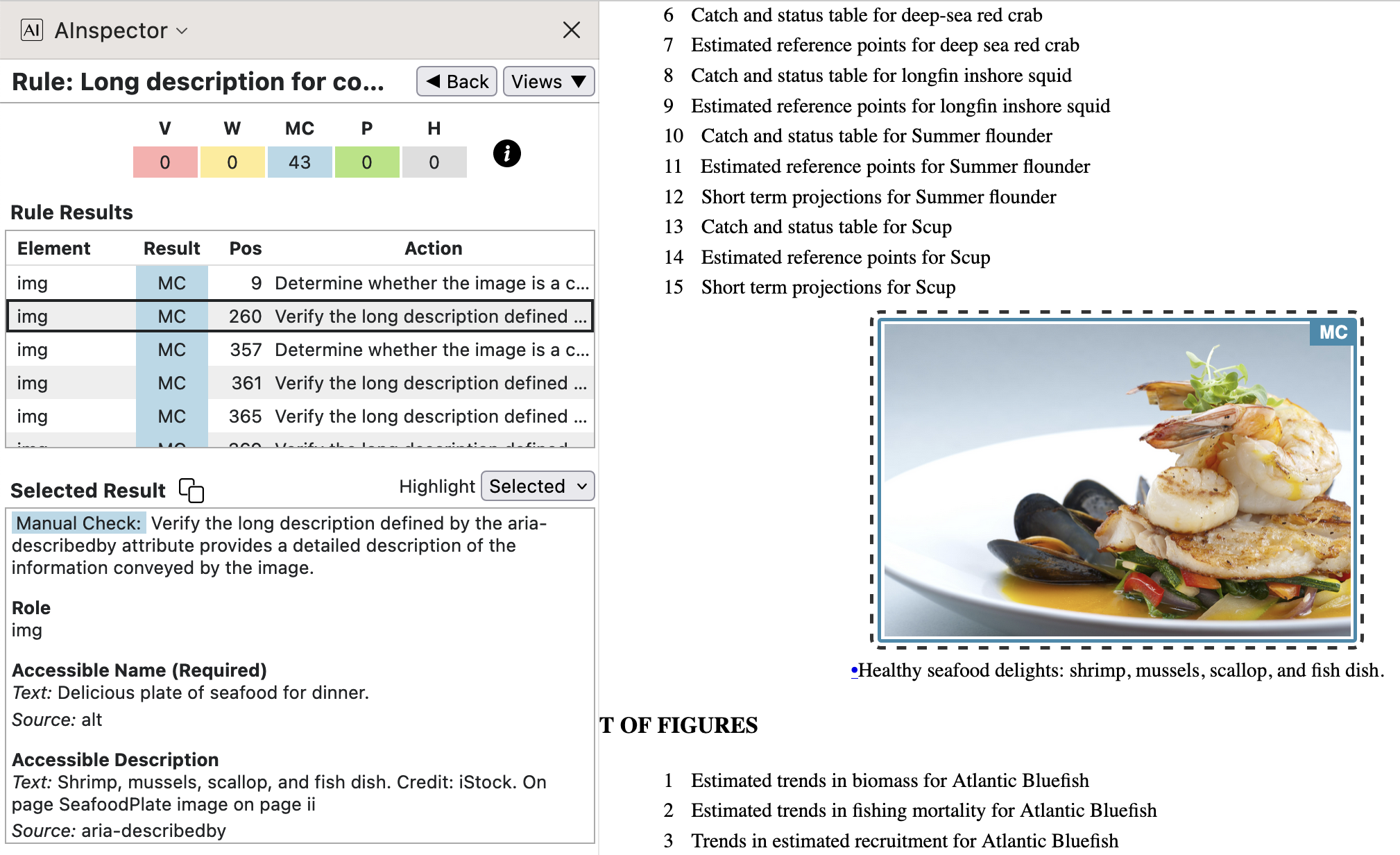
It is part of the usual editorial process to check the entries in any Glossary, particularly the ‘Photo Gallery’. Insertion of the photos themselves and their Glossary entries is done using a special LaTeX environment with coding designed to ensure all tasks are done consistently.
- The NOAA logo serves also the purpose of being the clickable anchor of the ‘skip to Main’ link at the
beginning of the document.
This explains the final portion of the
- 1.1.1 ‘Use MathJax for mathematical expressions’
Use of Mathematical expressions in this document is limited to stating the names of statistical variables, and specifying a value or range of values. For these the variable name serves as a link to a Glossary entry describing the purpose of the variable. MathML is thus not required to convey the meaning; ordinary text is sufficient to express an equality or range of values. Hence MathJax support is not incorporated in this HTML, though it could have been if there were more involved mathematical expressions.
The MC is requesting that all 43 images be checked; but certainly images of mathematical expressions are not being used.
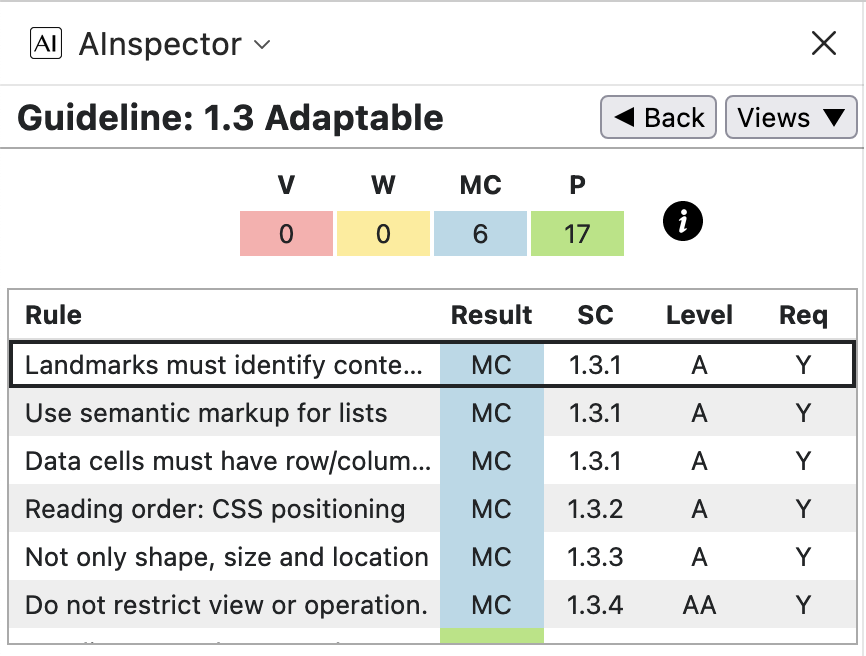
WCAG Guideline 1.3: Adaptable
- 1.3.1 ‘Landmarks must identify content regions’
The primary ARIA ‘Landmarks’ (BANNER, COMPLEMENTARY, MAIN, CONTENTINFO) correspond to the main top-level PDF document structure elements. For ‘Regions’ we have each section under ‘MAIN’, and also the ‘NAVIGATION’ sections — Table of Contents, List of Tables, List of Figures, and each of the 5 Glossaries (incl. the ‘Photo Gallery’).
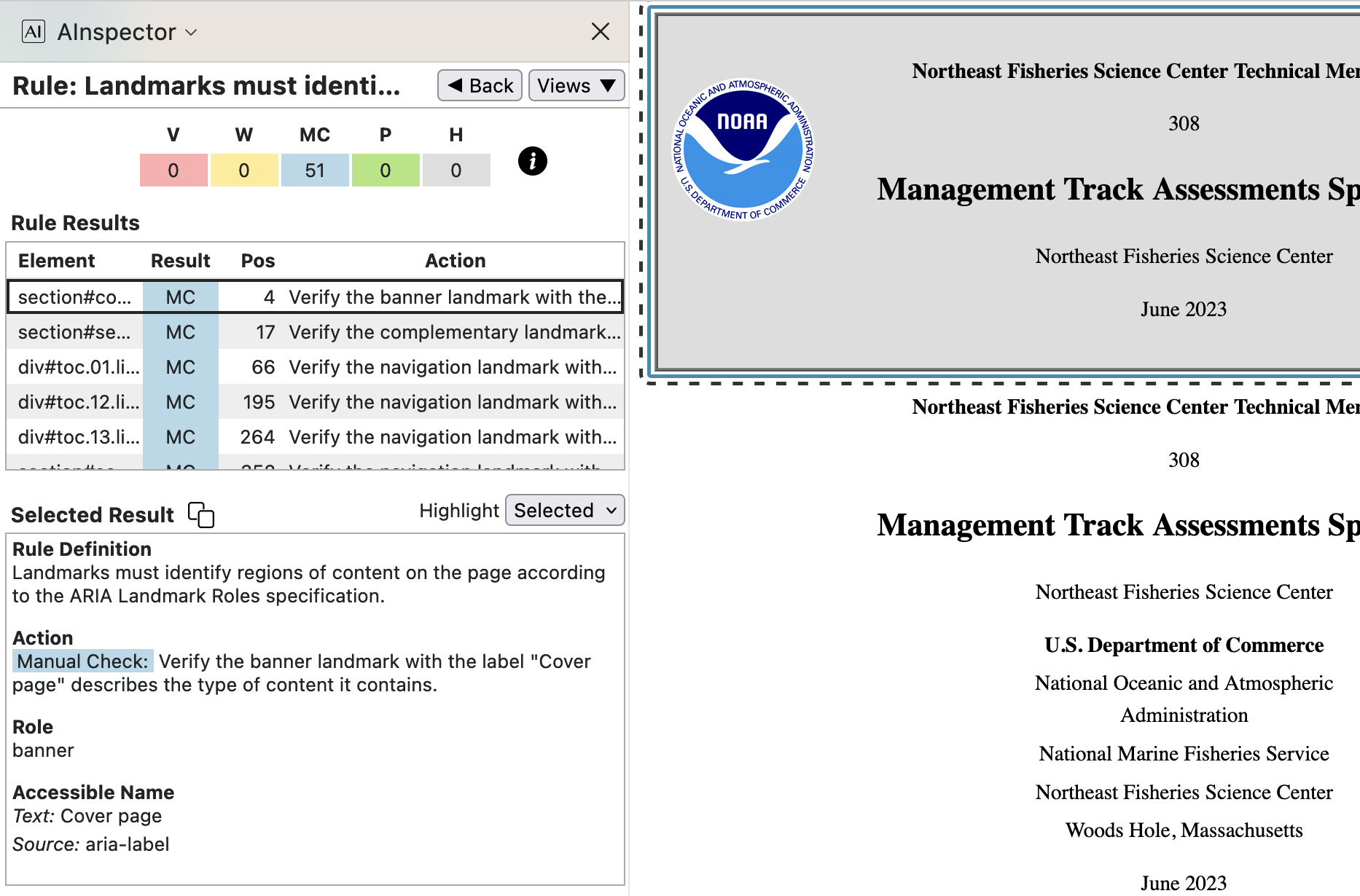

This structure is imposed within the LaTeX processing to build the PDF document. Other tests for ‘Landmarks’ with these stated roles give ‘Pass’, so the MC here is of the kind to ‘Verify … ’. Testing can/should be done in a structure-aware PDF browser (e.g., Acrobat Pro) and with PDF/UA validation software, to ensure that there is no error in other parts of the structure tree which might then have a wider effect.
- 1.3.1 ‘Use semantic markup for lists’
Most enumerated or bulleted lists use semantic tagging with
<ol>or<ul>, and items using<li>structures, perhaps with an attribute to specify the numbering or bullet style. These come from<L>and<LI>structures in the PDF tagging, or<TOC>and<TOCI>structures for lists of hyperlinks in the Table of Contents, List of Tables, List of Figures and Glossaries. Particularly for these latter, a CSS style class has rules to determine how the bulleting is done or suppressed.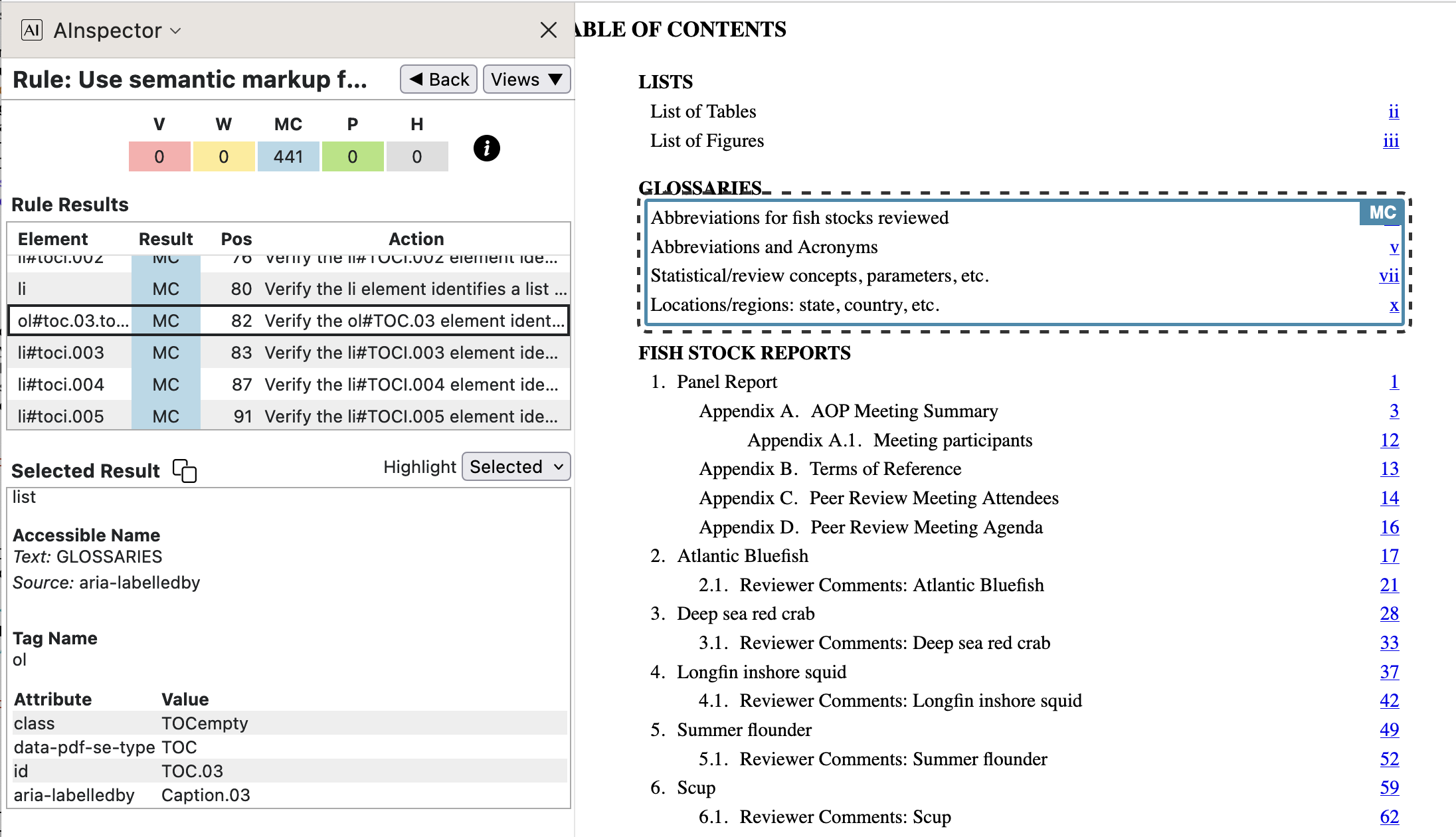
The Table of Contents is typically a structure of nested lists, which can be rather complicated. When sectioned into sublists, a heading can be provided for a
<TOC>as a<Caption>structure, which must occur before the<ol>or<ul>within the HTML version. Anaria-labelledbyattribute then associates the heading with the list structure it refers to. This is how the word ‘GLOSSARIES’ becomes the ‘Accessible Text’ for a sublist in the image above. For a list item, the ‘Accessible Text’ is generally created from the contents of that item, as in the image below.
\contentsline {subsection}{\numberline {Appendix C}Peer Review Meeting Attendees}{27}{subsection.1.C}%The codeline shown, from the
.tocfile, generates what is seen visually in the PDF, and with modified macro expansions also the structures with accompanying attributes. The grouping{Appendix C}is used multiply, as a label and in ‘Accessible Text’ for a hyperlink anchored on the visible page number, calculated by subtracting from 27 the number of front-matter pages, namely 13.The Manual Checking here is asking to ‘Verify’ that an element ‘identifies a list item element in a meaningfully grouped list of items’. This will certainly be the case with list structures that were created using LaTeX environments
\begin{enumerate},\begin{itemize}and\begin{description}, or other intricate constructions such as with\contentslineand\numberline. Thus this check is largely part of normal editorial work in the preparation of the PDF.One difference from normal editing, however, is being able to include the purpose of a list, without adding to visual content, using an
aria-labelattribute on the<L>structure; see image from the PDF, at right below.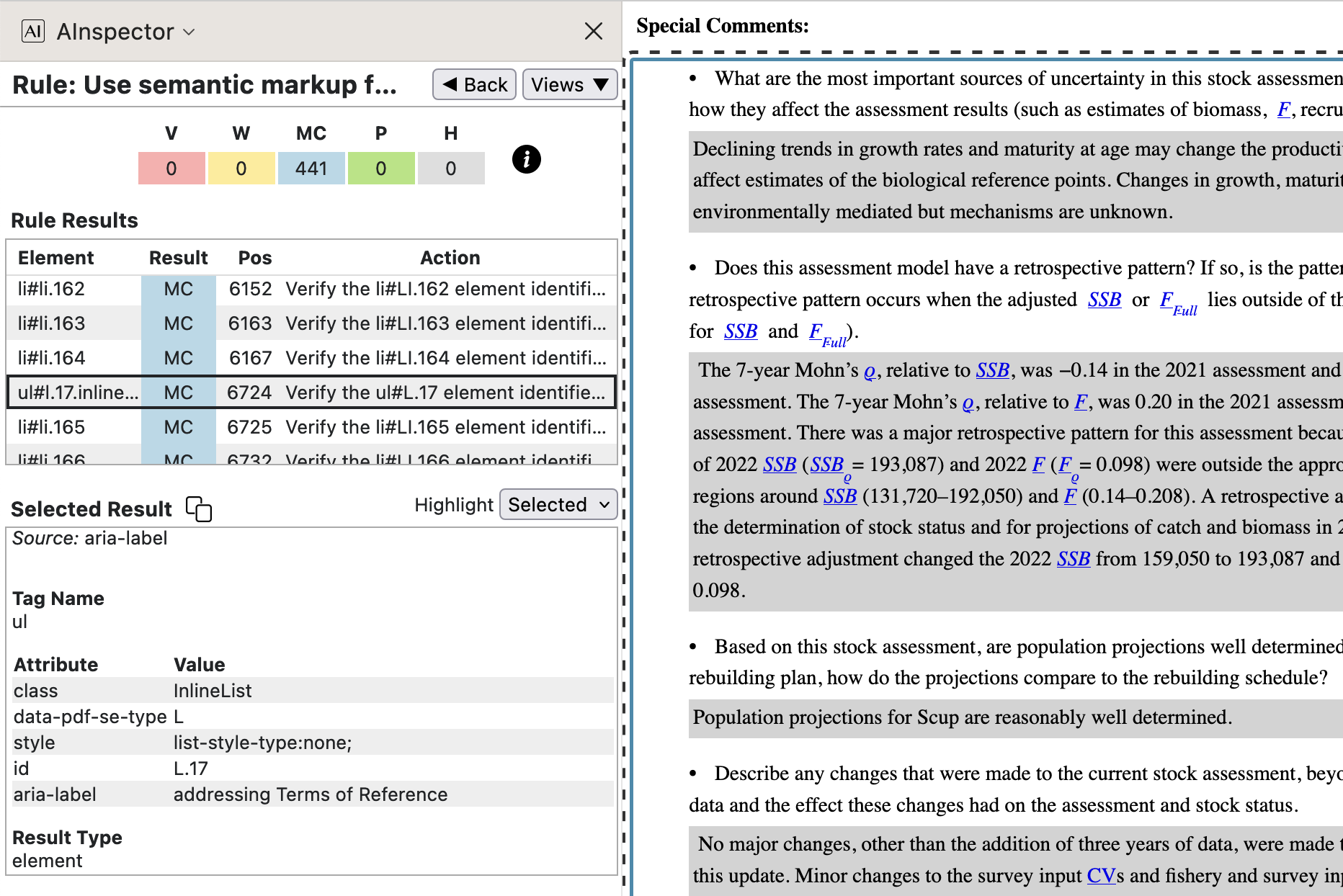
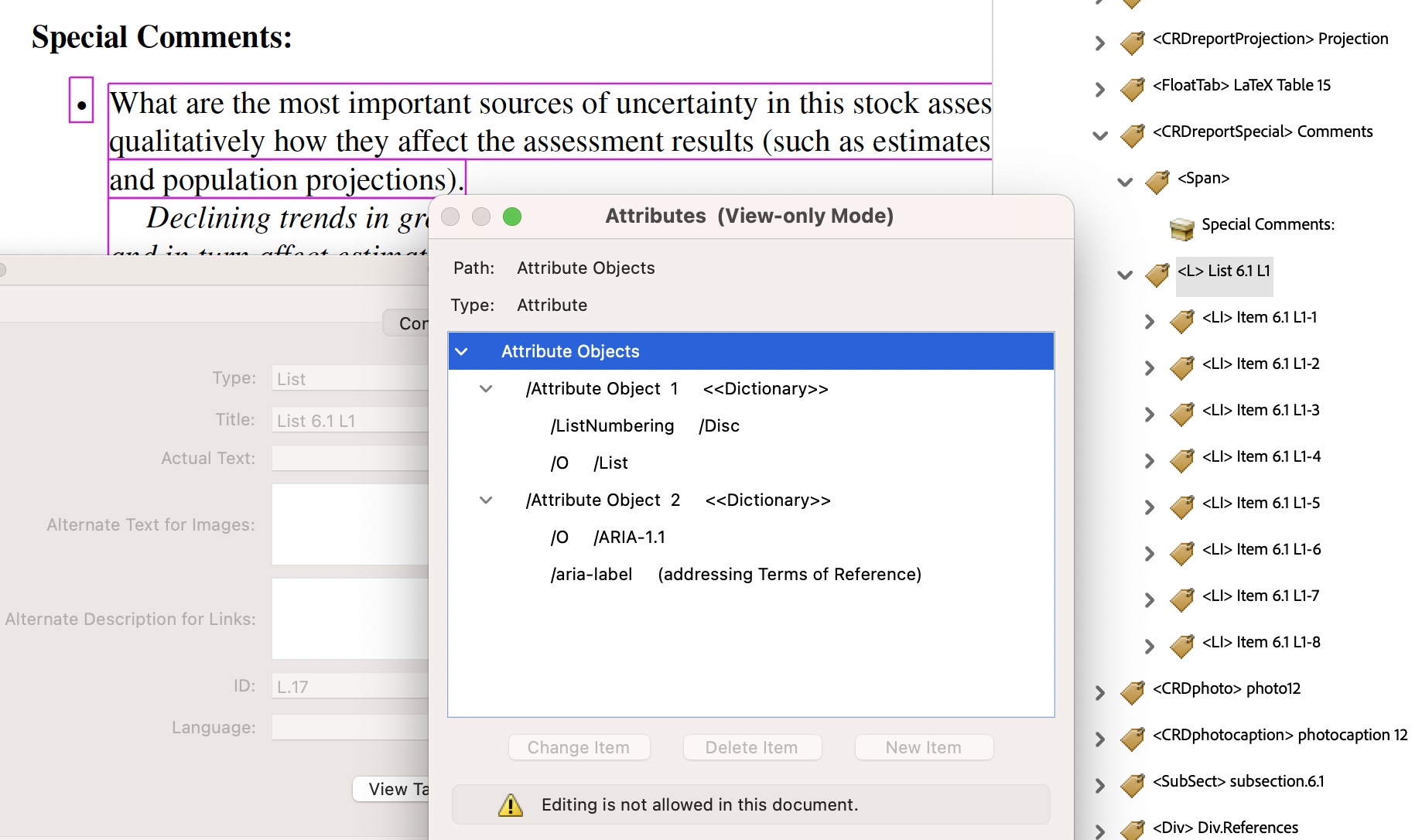
However, the above do not cover all ways to declare a list structure semantically, as the following examples show.
-
In the image below, Editorial Notes are typeset as separate paragraphs, starting with a bold-faced label. The whole paragraph has ARIA attributes
role="listitem"andaria-labelledby="CRDclause.1", which latter name is for the label. The name ‘/CRDclause’ is used both for the structure, with ‘RoleMap’ to/P, and as a name for a CSS class. In this way we emulate the semantics of a captioned ‘description list’ using just<div>,<p>and<span>HTML tags. Furthermore, thearia-*attributes convey brief text giving the purpose of each element.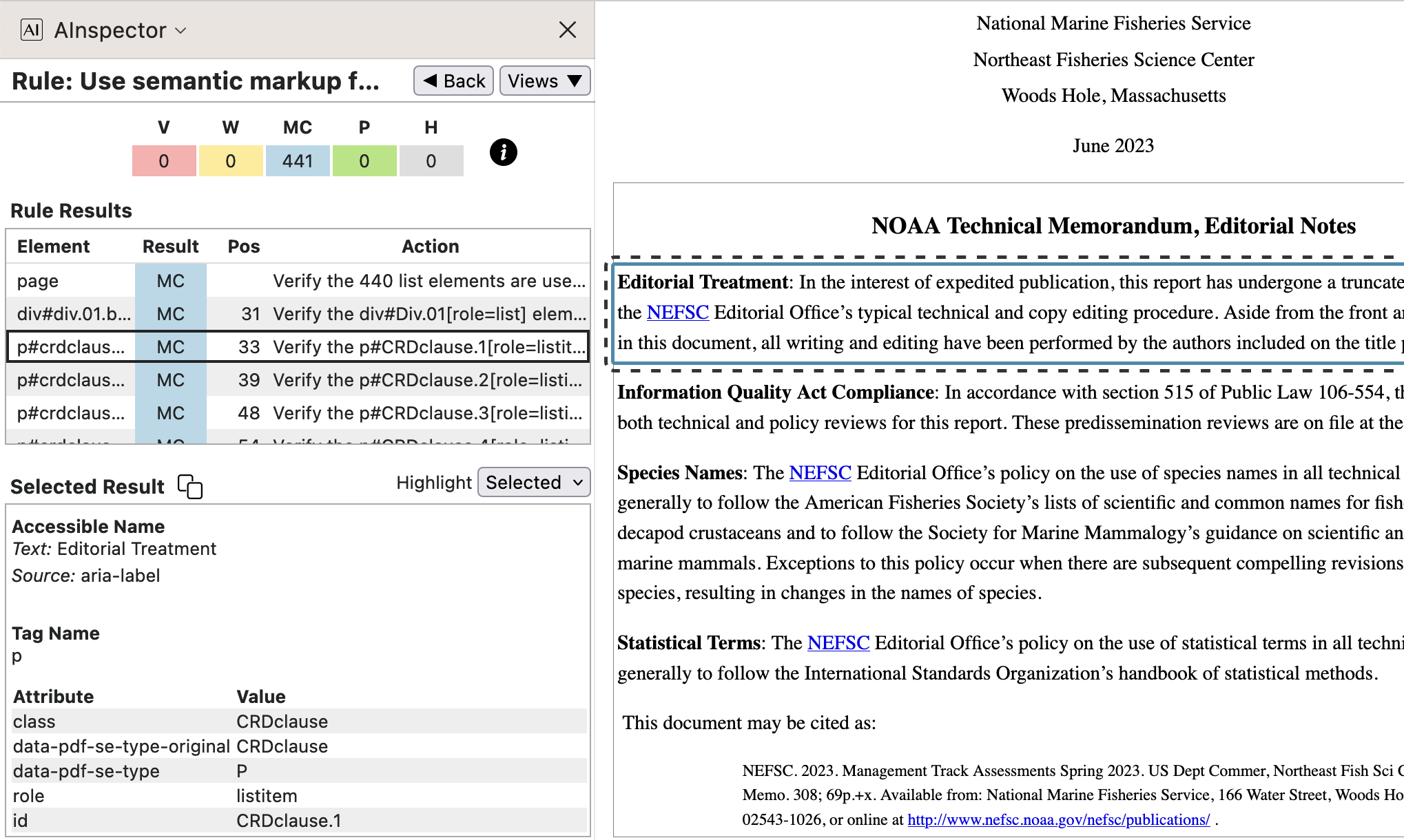
-
In the images below we see how the collection of AOP panellists are presented inline within the PDF, but enclosed in a Custom structure with name
/AOPauthors. Using a ‘RoleMap’ entry of/Divthis becomes a<div>within the derived HTML, having associated ARIA attributes ofrole="list"andaria-label="Assessment Oversight Panel". For the individual panellists the Custom structure is/PRPpanellist, which has a ‘RoleMap’ entry of/Span, with attributes and class name as seen in the right-hand image below.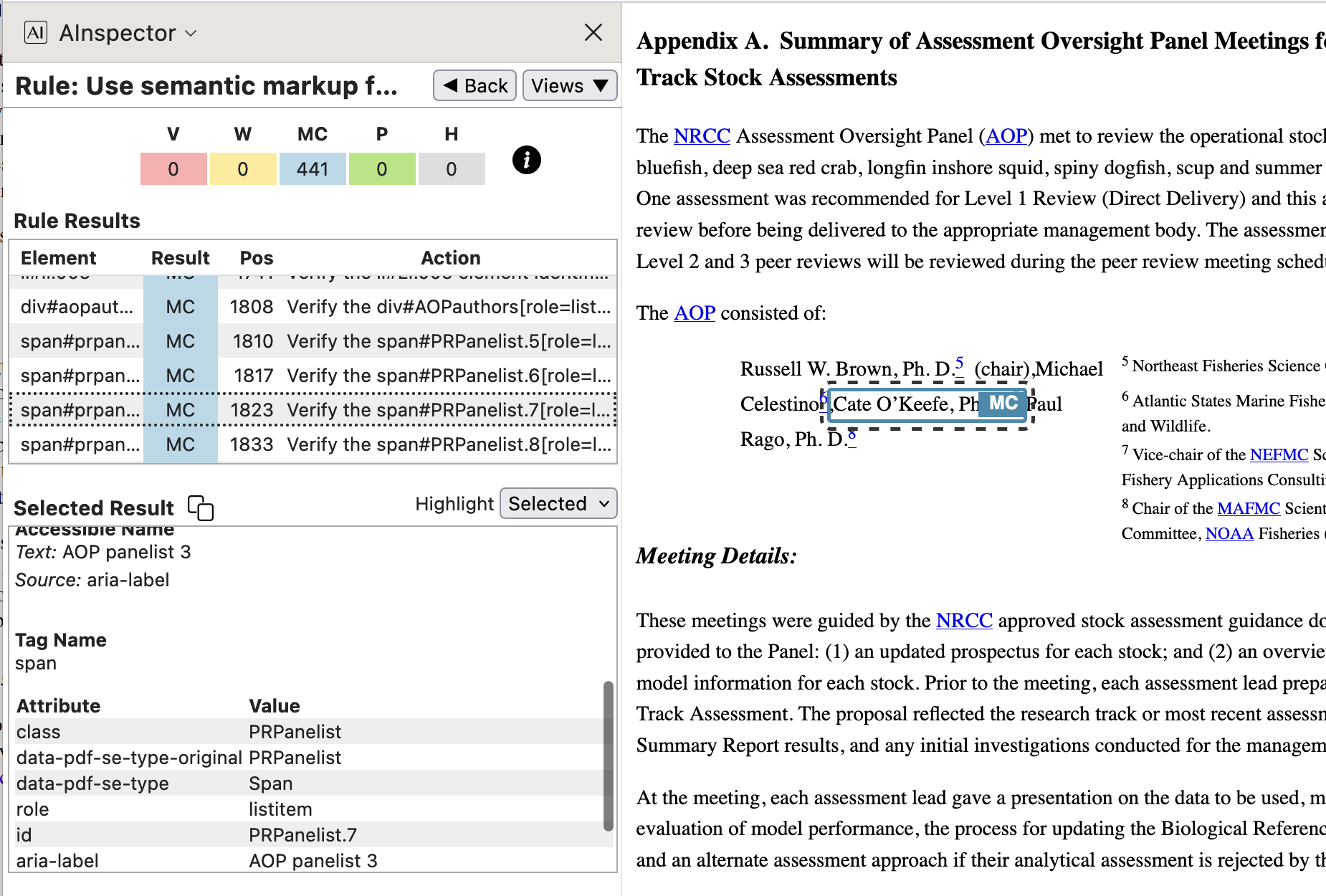
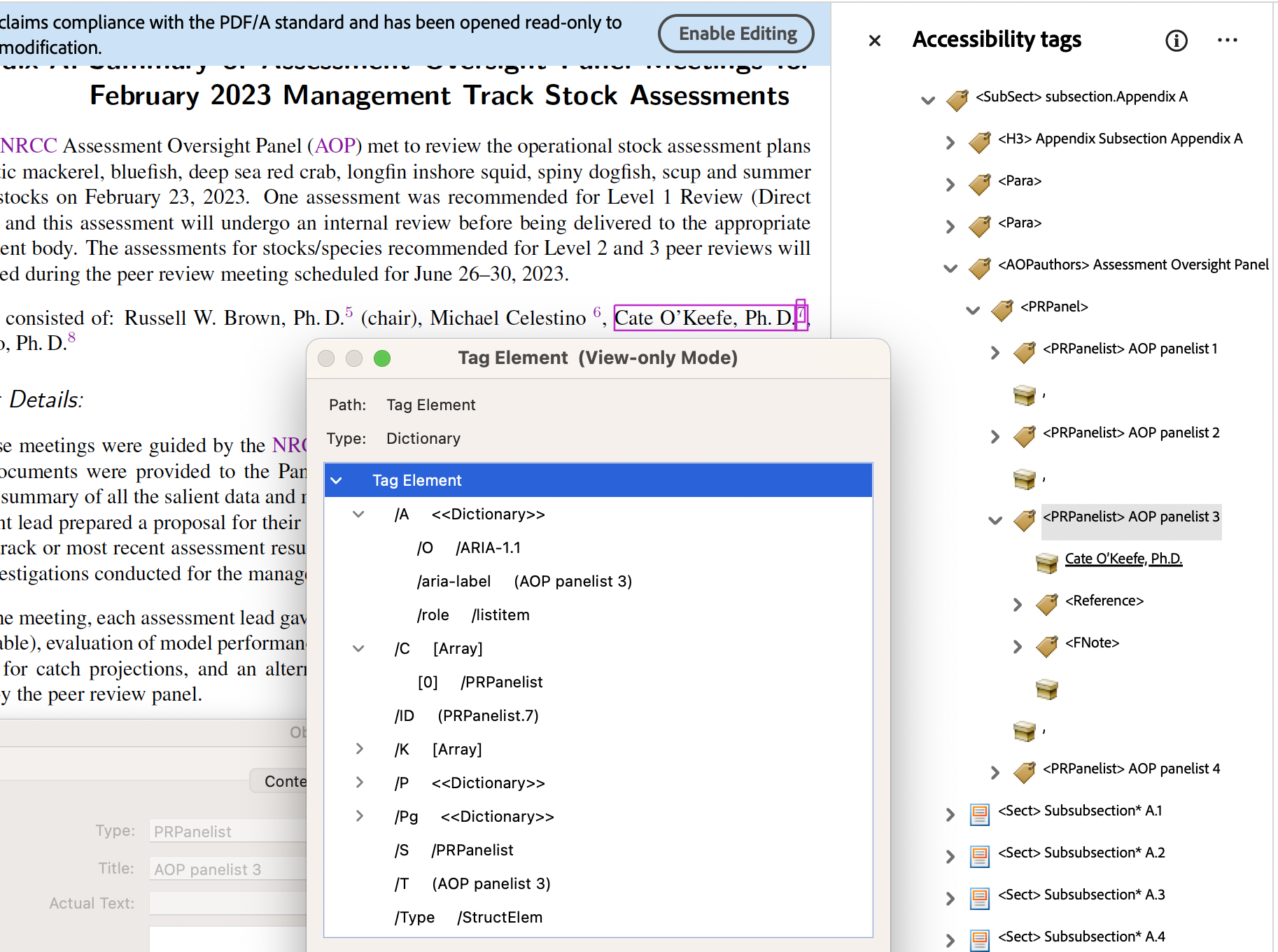
Note how each panellist has an accompanying affiliation which is presented as a footnote in the PDF, but which follows immediately afterwards in the structure tree, hence also within the HTML. These affiliations have a CSS class with rules to float the content to the right side of the parent rectangle, at reduced size. The ARIA attribute of
role="listitem"allows Assistive Technology to inform a non-visual reader about the list-like aspect of this kind of information; which a fully-sighted person would deduce from layout alone within the PDF.
-
- 1.3.1 ‘Data cells must have row/column headers’
The presence of a ‘Headers’ attribute for data cells is easily checked algorithmically. However, when a data cell is empty, it could be that there is no value to be displayed, or that the cell is for layout purposes only.
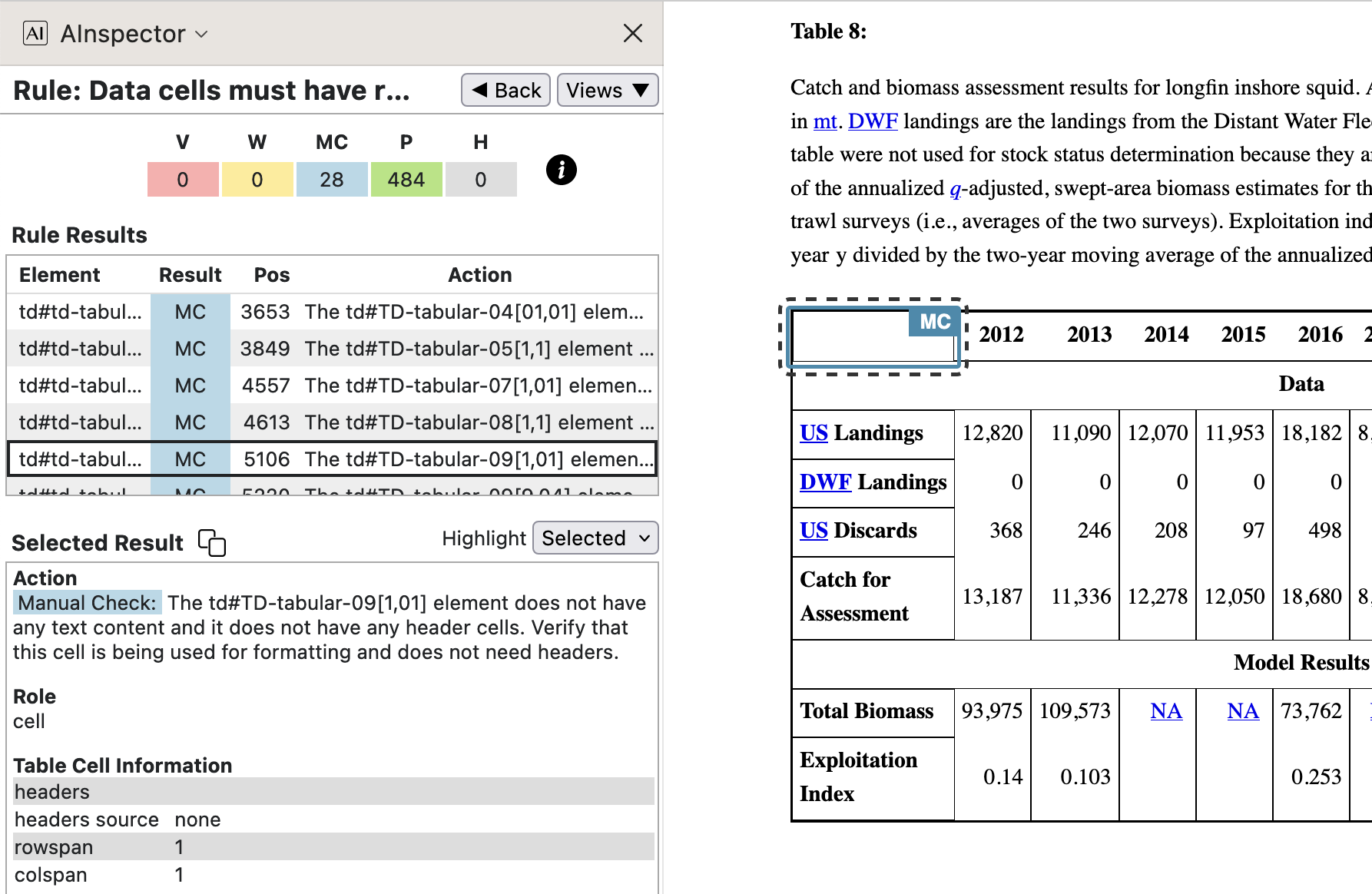
In this document, PDF or HTML version, there are 28 such cells which are deliberately blank, without header attributes. This can be checked manually. The remaining 484 data cells have been successfully checked for headers.
- 1.3.2 ‘Reading order: CSS positioning’
This check concerns the use of subscripts in the names of statistical variables. These are all constructed in a similar way within the LaTeX coding, which places content in the correct reading order. So checking for just a few of these should be sufficient to be sure that all are OK.
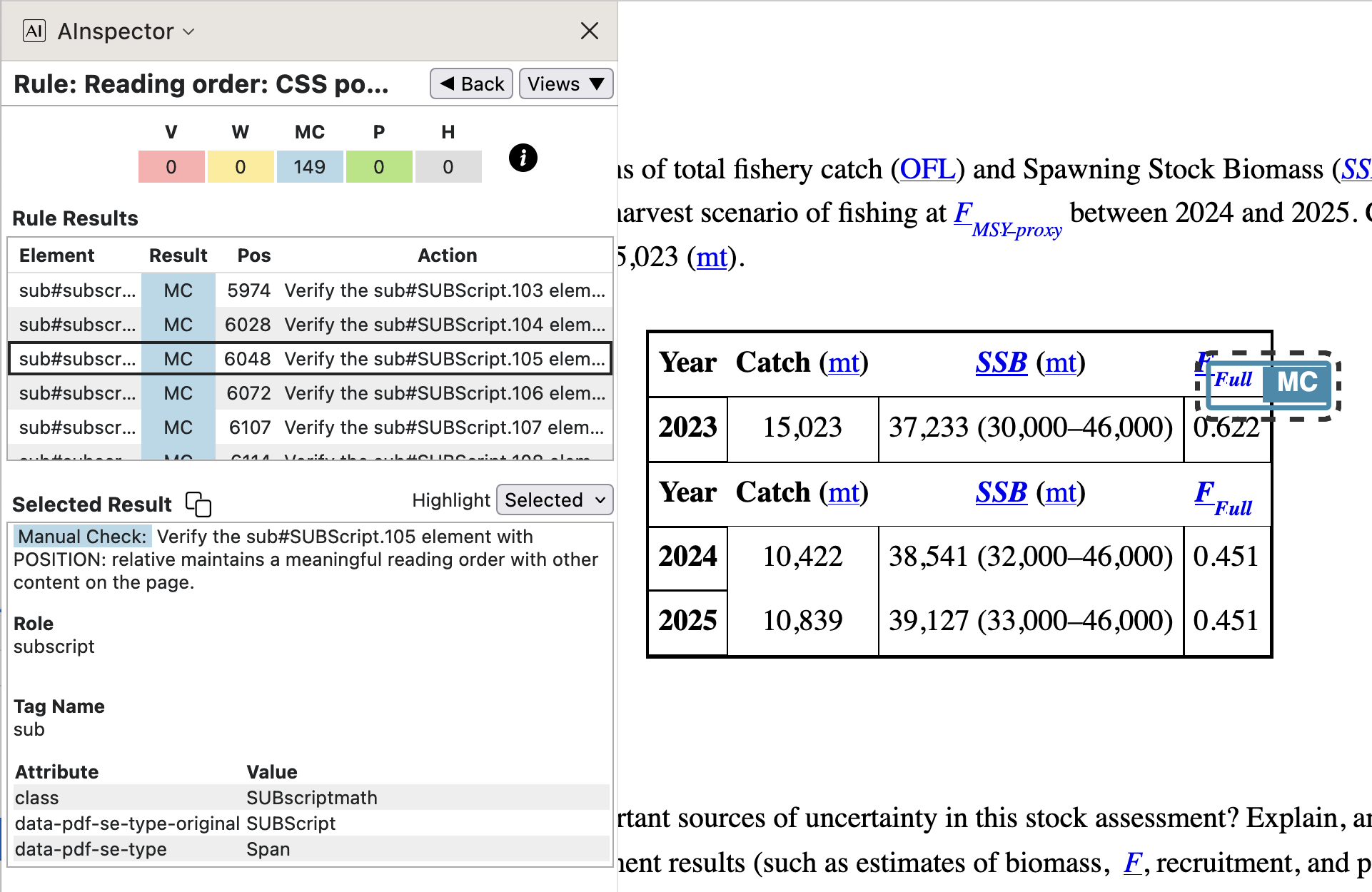
- 1.3.3 ‘Not only shape, size and location’
This check is very wide-ranging, covering aspects of the document design, technical implementation of accessibility features, and author/editor's use of such features. It certainly cannot be checked in any algorithmic way.
In practice the approach should be that in all situations where a fully-sighted reader gains understanding of the content due to font size and style, visual layout or special placement of textual content, there should be some
aria-*(or other) semantic attribute(s) which can be used to explicitly convey what would otherwise be conveyed implicitly. - 1.3.4 ‘Do not restrict view or operation’
Perhaps the best tests here are to view the document, both PDF and HTML versions, on a smartphone. Ensure that, for both horizontal and vertical orientations, there is smooth scrolling that allows access to all parts of the document. This certainly needs Manual Checking. Also do similar tests, Zooming-in and Zooming-out on different-sized monitor screens.
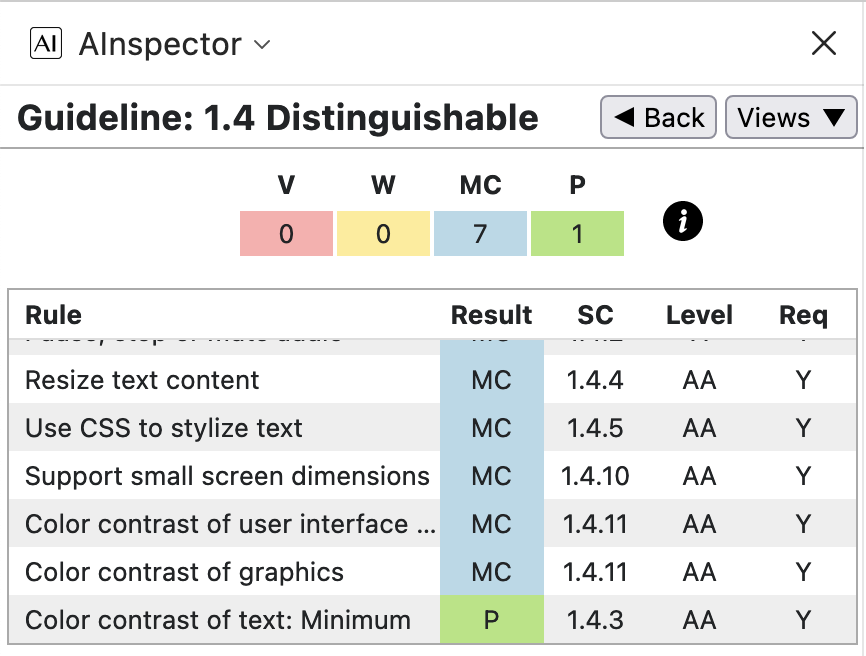
WCAG Guideline 1.4: Distinguishable
Some of the tests in this category apply to the document as a whole, not related to any particular structural element, and thus not checkable algorithmically.
- 1.4.1 ‘Use of color’ — see image at left above.
Color is used to indicate hyperlinks and Glossary item usage (an Abbreviation, say). These elements have accompanying
aria-*attributes which identify their specialised purpose and link target. - 1.4.2 ‘Pause, stop or mute audio’ — see image at 2nd from left above.
There is no audio content, so this kind of situation does not arise.
- 1.4.4 ‘Resize text content’ — see image at 2nd from right above.
With the specialised scientific content, especially the wide tables and extensive discussion, we do not feel that 'Reflow‘ is appropriate. Scrolling is quite suitable.
- 1.4.5 ‘Use CSS to stylize text’
Although an image may contain text, there is no image being used as a picture of text for styling purposes.
- 1.4.10 ‘Support small screen dimensions’ — see image at right, in the group of 4 above.
With the specialised scientific content, especially the wide tables and extensive discussion, we do not feel that it is appropriate to force information into such small dimensions as 320 x 256, without scrolling.
- 1.4.11 ‘Color contrast of user interface controls’
As with SC 3.3, the reporting of all table rows (see image below) as being an ‘interface control’ is surely an error in the AInspector programming. This issue is fixed with AInspector v3.0. Now, however, it reports MC being needed as a AA level check for all internal hyperlinks. But under SC 1.4.3, a value of 9.4 is calculated for hyperlink text on a white background.
The intention was for this document to have no interface controls other than those provided by the reader software. Thus this test should be automatically a Pass, or simply deemed ‘not applicable’.
- 1.4.11 ‘Color contrast of graphics’
The computer-generated graphs and charts generally have high contrast. Photographs and the fish illustrations are primarily for decorative purposes, so there is no specific information that they are required to convey. Besides, those photographs and illustrations mostly appear on other NOAA websites, for which similar accessibility requirements apply. Thus there is no detailed extra checking needed for this rule, beyond assessing the suitability of the chosen images for printed publication.
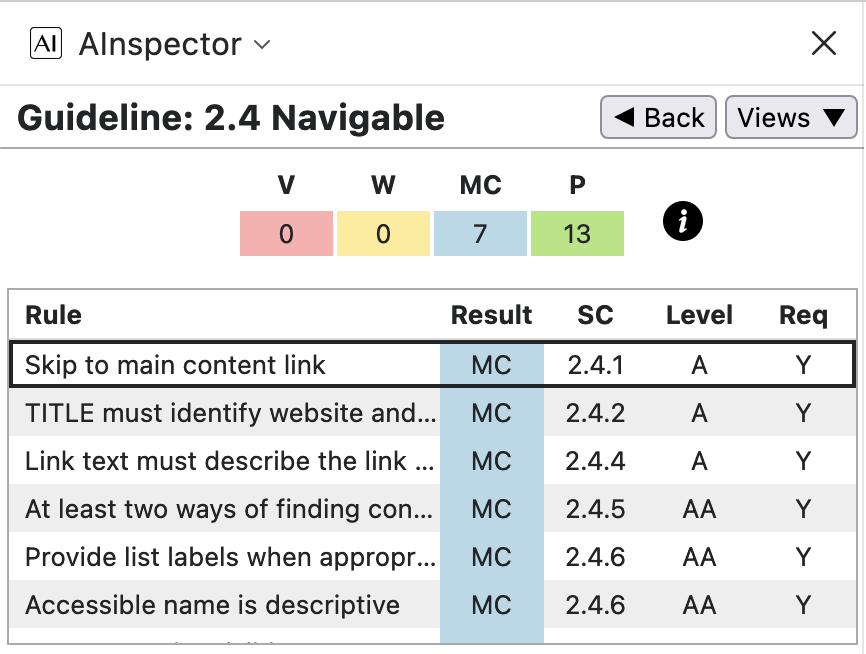
WCAG Guideline 2.4: Navigable
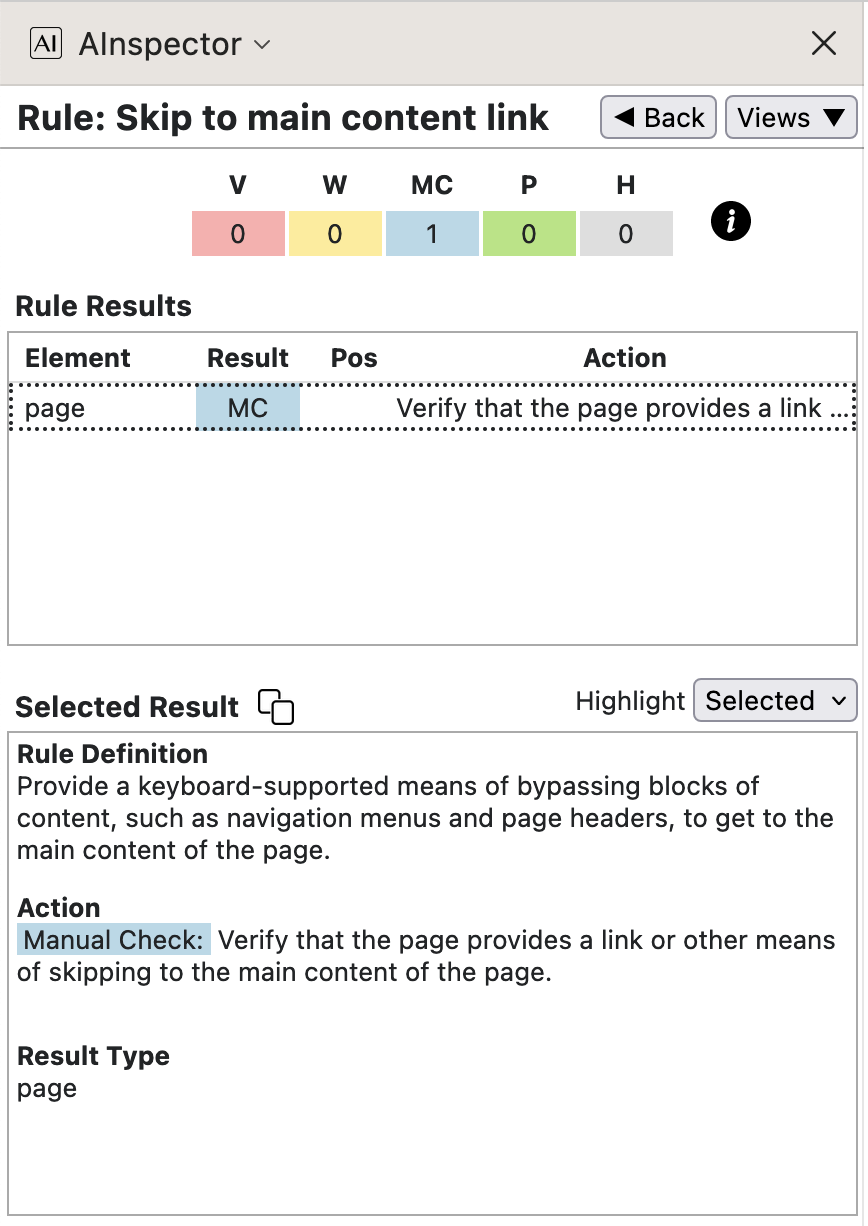
- 2.4.1 ‘Skip to main content link’, and multiple Pass tests for Landmarks
The logo on the cover page has a dual use, being the anchor for the ‘Skip to Main’ hyperlink, bypassing all document front-matter.

AInspector gives a Pass for many rules concerning the use of ARIA ‘Landmarks’; in particular the top-level ones of ‘BANNER’, ‘COMPLEMENTARY’, ‘MAIN’ and ‘CONTENTINFO’. The following image shows this top-level structure in FireFox's Accessibility panel of its ‘Web Developer Tools’.
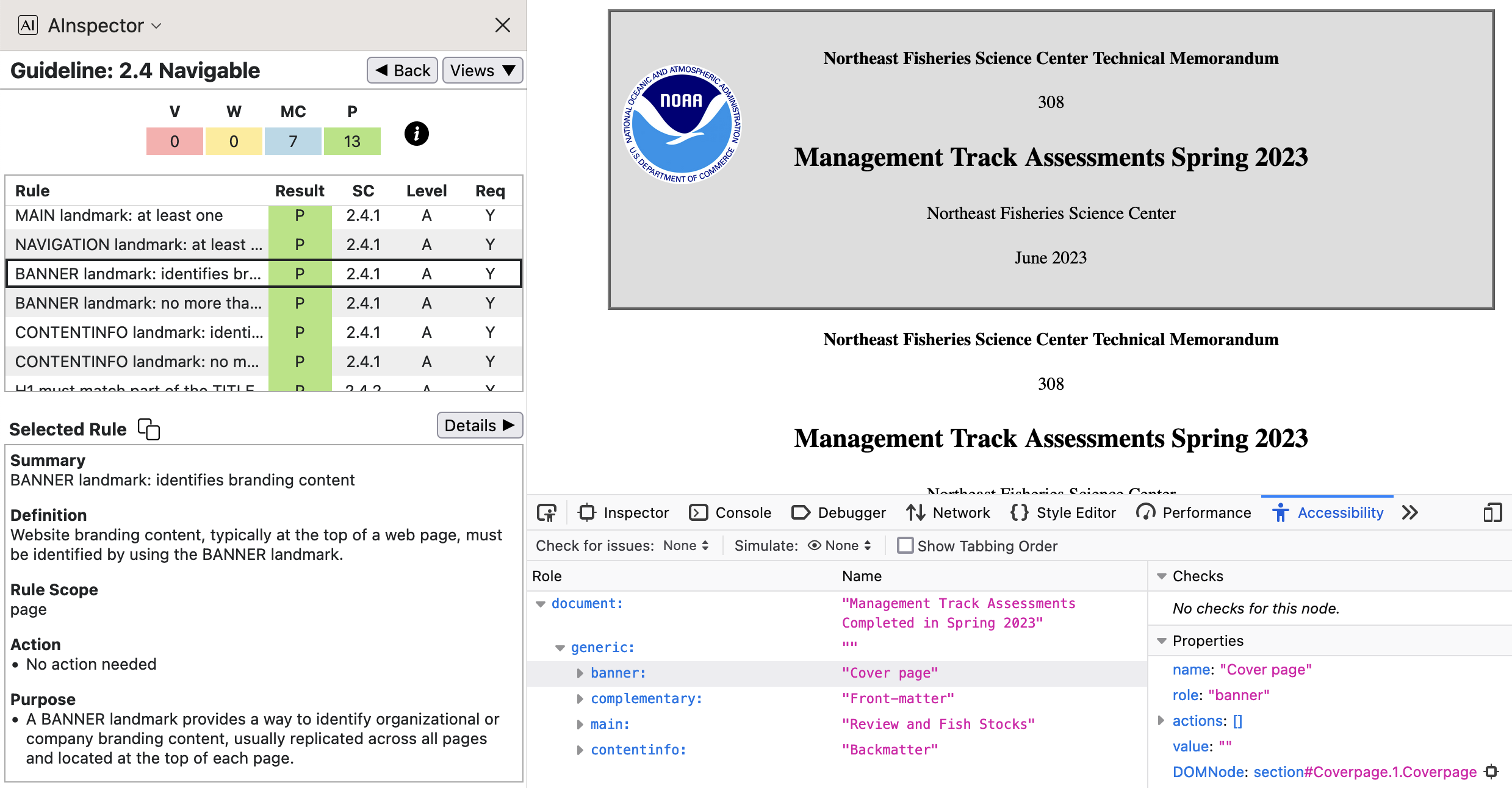
The ‘Accessibility Tree’ is derived from the Tagged PDF Structure Tree, after Role Mappings have been applied. The result is close to, but not exactly, an isomorphic tree structure.
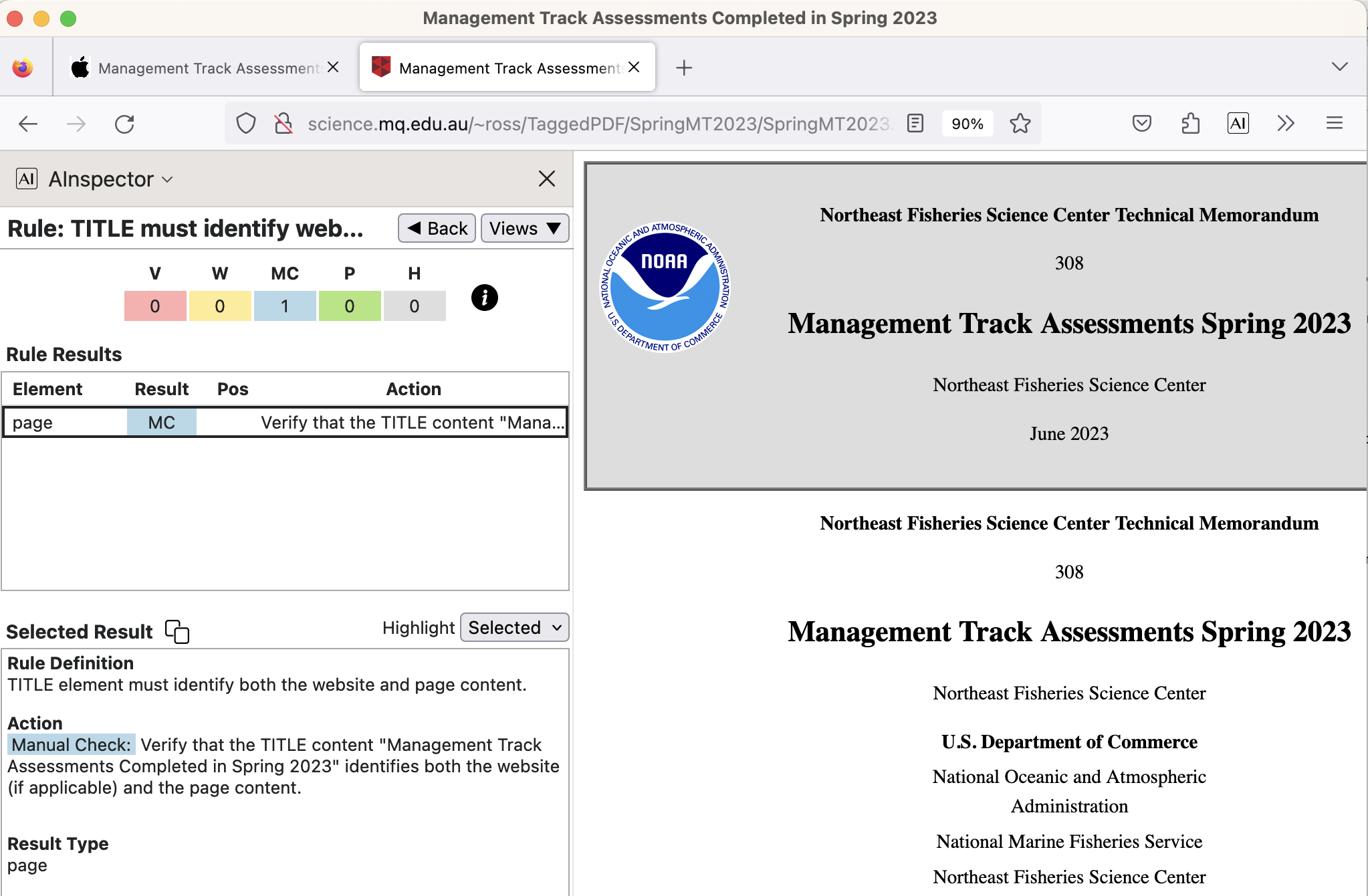
- 2.4.2 ‘TITLE must identify website and page‘ and be H1
The document's title is used in multiple places, including identifiers for both the Browser window and tab. Within the main frame it is slightly abridged, within the derivation of the Cover page and Title-page.
- 2.4.3 ‘Sequential tab order of focusable elements must be meaningful’
Whereas AInspector checks all 1500+ hyperlinks, and other structures having a specified
tabindexattribute, to verify that the tabbing order is meaningful, there is no such check of the PDF with PAC 2021, or PAC 2024.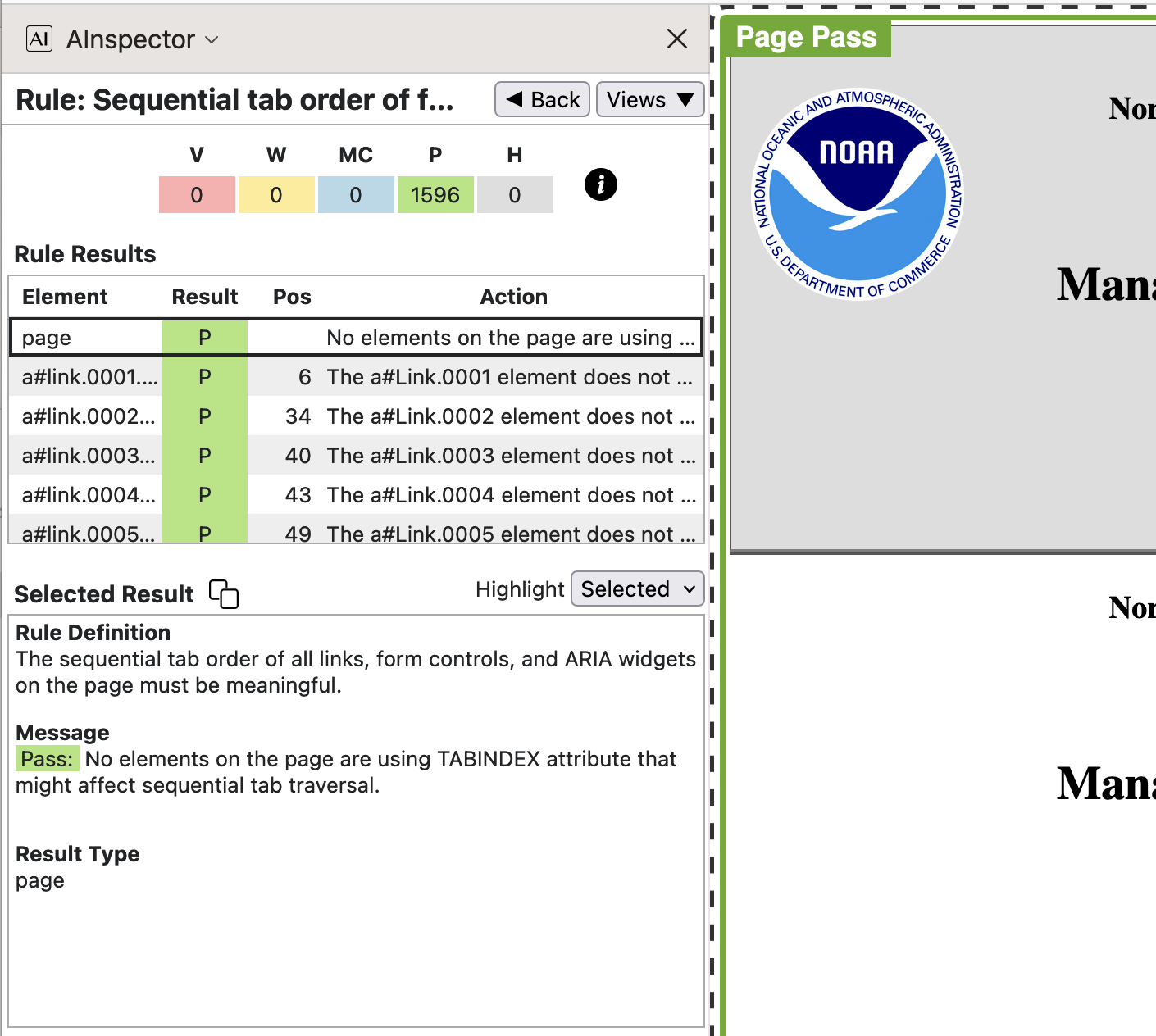
- 2.4.4 ‘Link text must describe the link target’ and be unique
This is perhaps the most significant rule for Accessibility, especially in a document having 1500+ hyperlinks, mostly internal. In particular, when navigating using AT or via the keyboard skipping from link to link, it is important to know where a link will take you before choosing to follow it. What kind of information will be found there? And having followed a link, did it take you to what was expected?
To address such questions ARIA uses the concepts of ‘Accessible Name’ and ‘Accessible Description’ which can apply to structural and semantic elements, including
<link>s. These concepts were described earlier, and how they are determined is summarised briefly above.It is preferable that the ‘Accessible Name’ should be unique in the sense that links having the same ‘Accessible Name’ should have identical target (value of the
href). Certainly there must be an ‘Accessible Description’ which allows to differentiate between links which do have the same name but different targets. For example, when navigating via a list of links only, removed from their original context in the document, then the Name and Description must be sufficient to determine which link to take, if either. In our example PDF and its derived HTML, there should be no such instances.No-one is ever going to manually check 1000+ links. With so many, we look here at examples of different usages of internal hyperlinks, with the ‘Accessible Name’ constructed for enhanced accessibility. Images below show how the required pieces of information are stored within the PDF file.
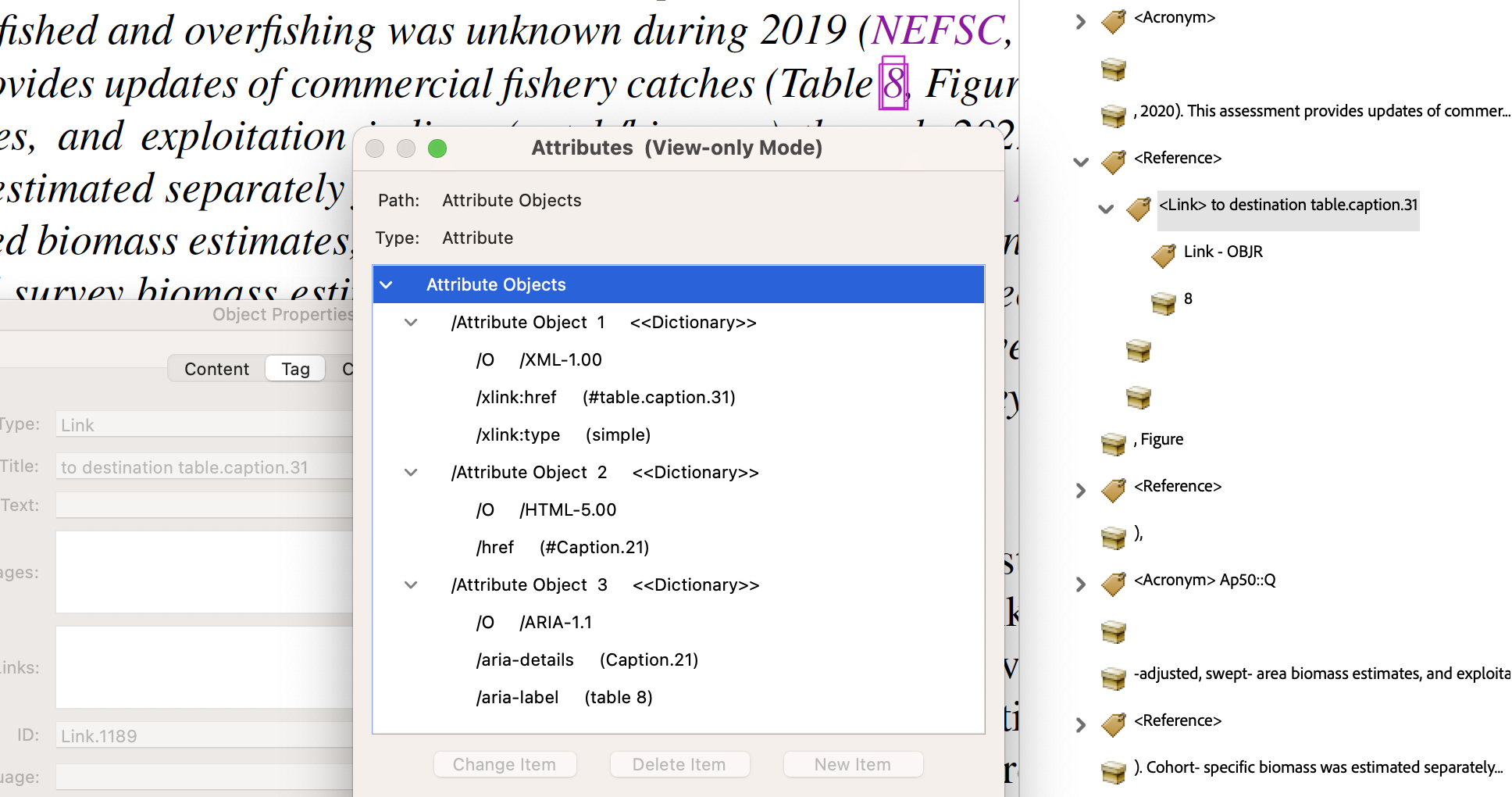
- Table of Contents, link to sectioning, starting on a particular page.
The anchor text is the visible page number, here the roman numeral ‘x’; this has MCID of 31, as seen near the bottom of the right-hand image below. The target destination is named
section*.11whereas the/SDis to the object numbered 2712. The Annotation itself is of type/OBJRstored as object numbered 457, referred to indirectly as a child of the<Link>structure.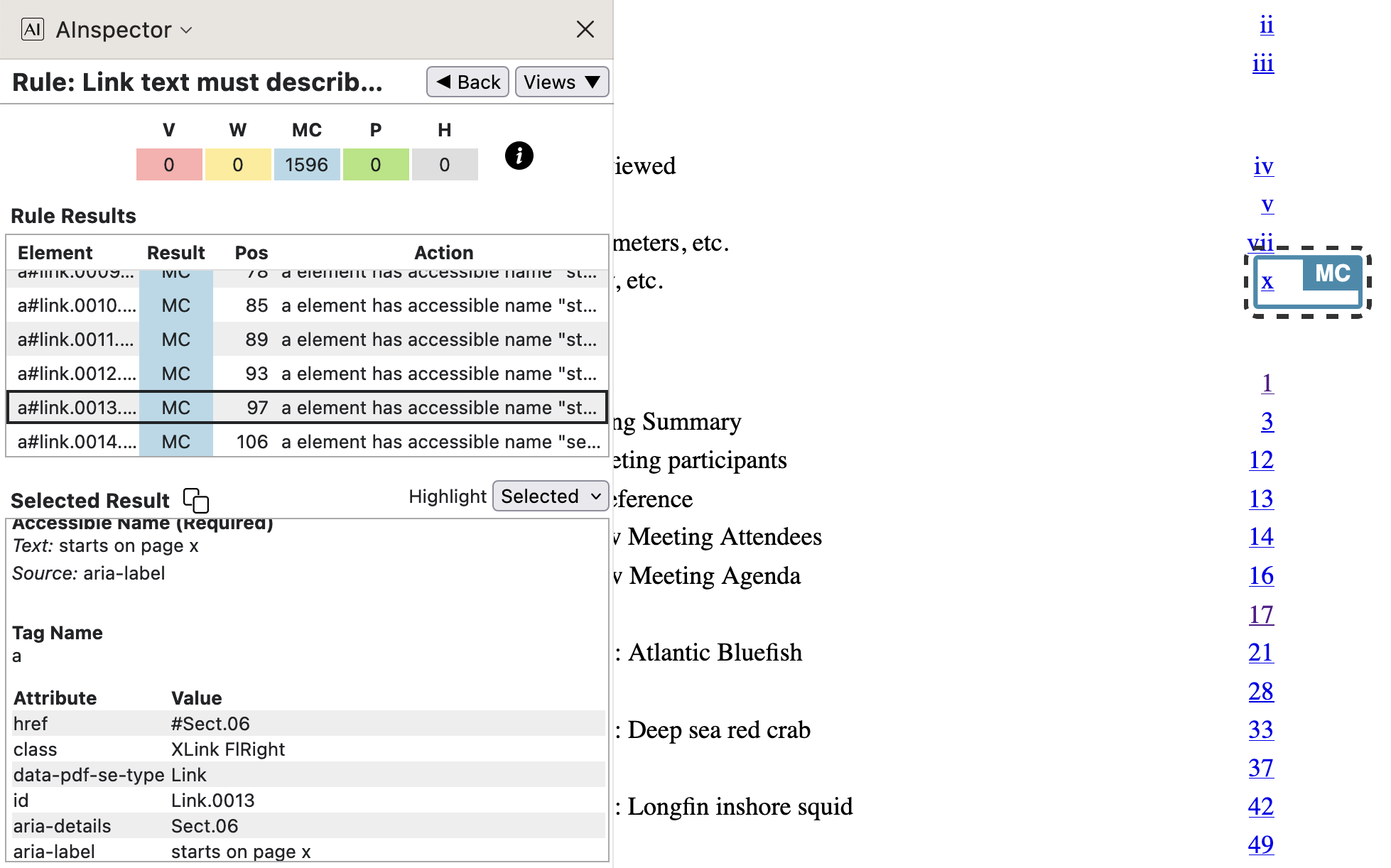
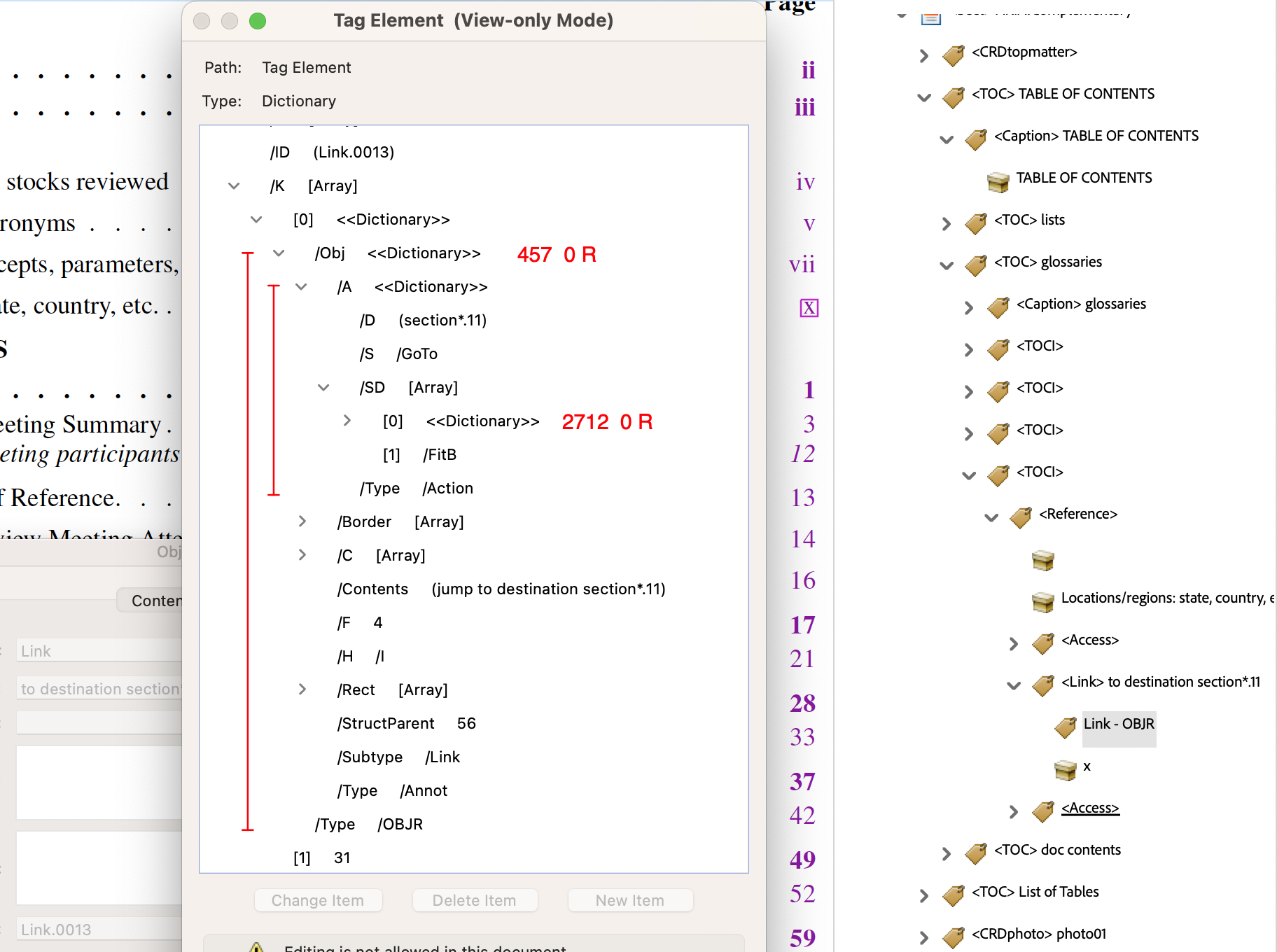
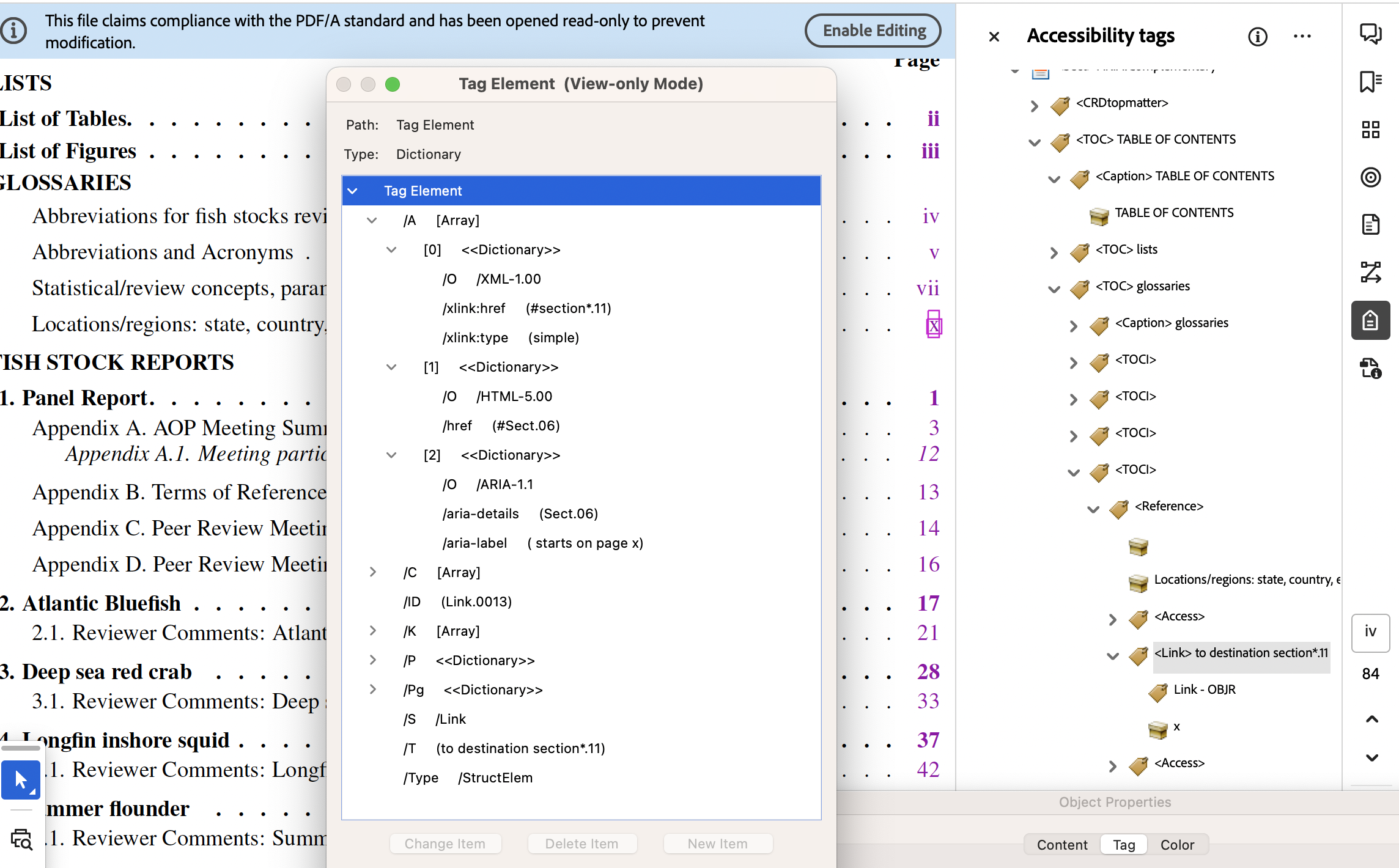
In the lower image we see the attributes used for exporting to other formats. For XML (exported from Acrobat Pro), the ‘Named Destination’
section*.11is used. For HTML the structure nameSect.06is provided as target, having also anaria-labelof ‘starts on page x’, as the ‘Accessible Name’. Within the HTML file the name (‘Locations/regions …’) of the Glossary occurs immediately preceding the link, so need not be repeated.At the LaTeX level, the information for the link comes from lines generated automatically during the processing, and written into ‘auxiliary’ files for a subsequent run.
- from
SpringMT2023.tocfor lines within the Table of Contents:\contentsline {subsection}{Locations/regions: state, country, etc.}{xiii}{section*.11}%
Note the virtual page number of ‘xiii’ is displayed visually as ‘x’ since there are 3 initial Cover/Title pages coming before roman numbering of front-matter pages commences. - from
SpringMT2023.tgxhaving tagging information from the previous run:\TPDFmakeSD{section*.11}{2712}{Sect.06}%
The latter code line, read during the setup for a job run, establishes the relationship between the ‘Named Destination’
section*.11, the PDF object ID 2712 of the target, and its structural nameSect.06. Such 3-way relationships are vital for working with ‘Structure Destinations’, since with just a single processing run the target object is processed well after links to it are needed. Thus we refer to the fileSpringMT2023.tgxas being a ‘Tag History’ file, for tagging.In this next example we give the LaTeX code first, for easy comparison with above. This time they are given the order in which they are read and processed.
- from
SpringMT2023.tgx:\TPDFmakeSD{subsection.6.1}{8830}{H3.19}%
- from
SpringMT2023.toc:\contentsline {subsection}{\numberline {6.1}Reviewer Comments: Scup{}}{75}{subsection.6.1}%
Subtract 13 (for 3 + 10 front-matter pages) from the virtual page number 75, to get the visual page number of 62 displayed as an arabic numeral.
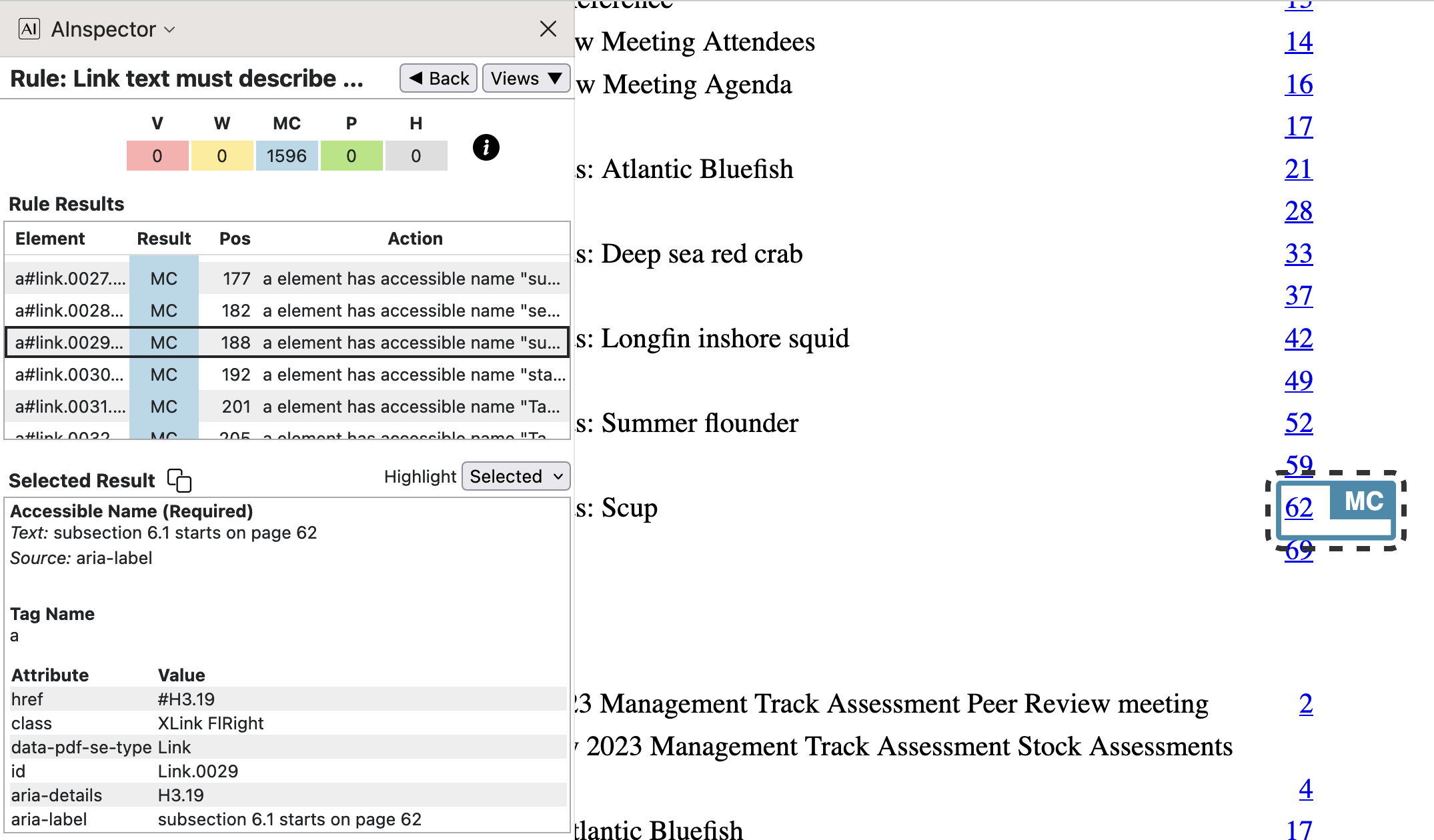
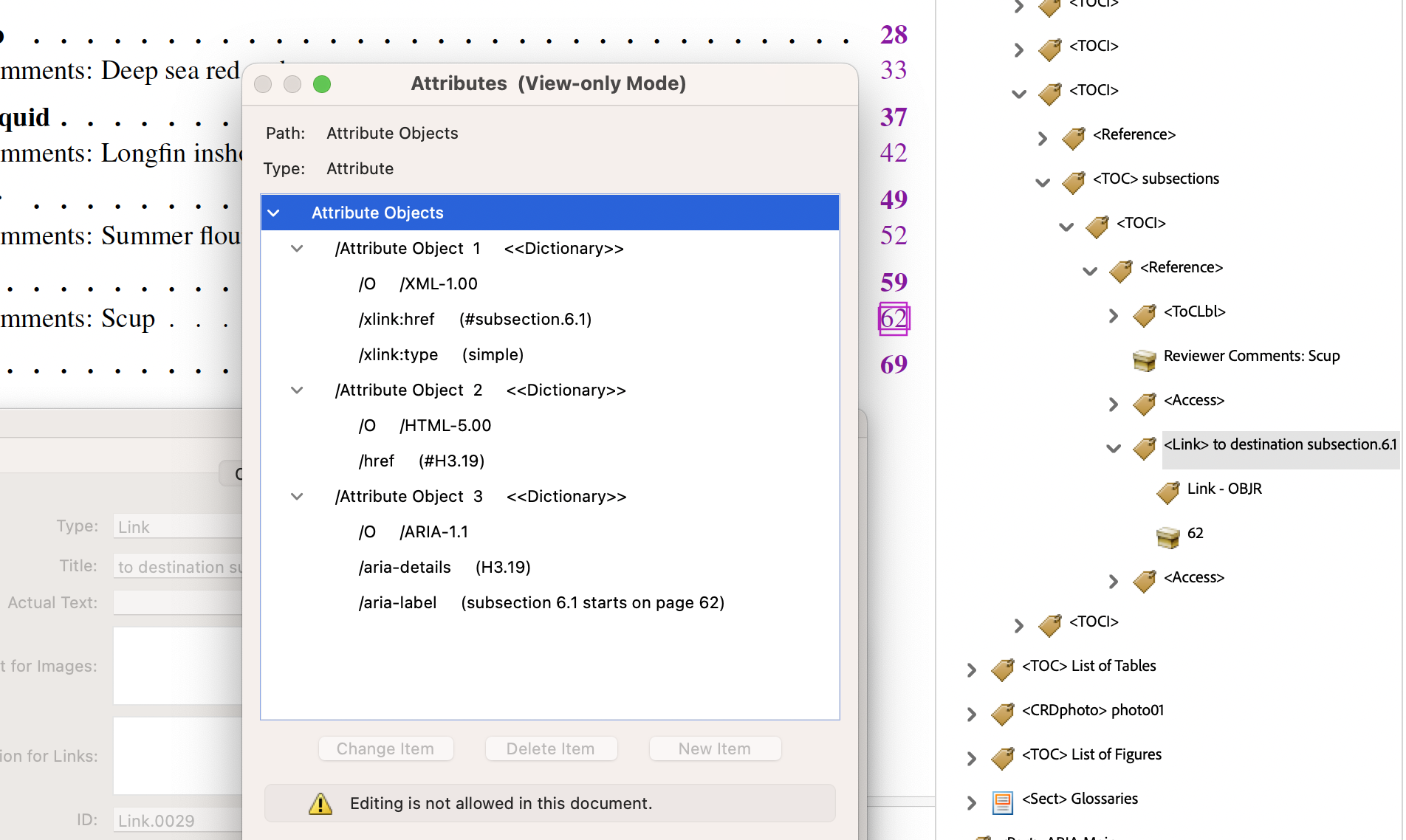
With a numbered sub-section, the label string ‘subsection 6.1’ is deducible from the available information. This is used within the
aria-labelattribute, for better understanding the target of the link. Now this is the heading of the sub-section, being the element namedH3.19. - from
- List of Tables or Figures, link to the caption of the Table or Figure on a particular page.
It is usual in LaTeX to specify a
\label{...}following the\caption{...}for a figure or table in a floating environment; i.e.,\begin{figure}or\begin{table}. This\labelprovides a user-defined identifier that effectively aliases an internally-assigned named destination for the caption's location within the PDF file. Thus it is the<Caption>structure which is referenced with the ‘Structure Destination’, but named according to the particular Figure or Table.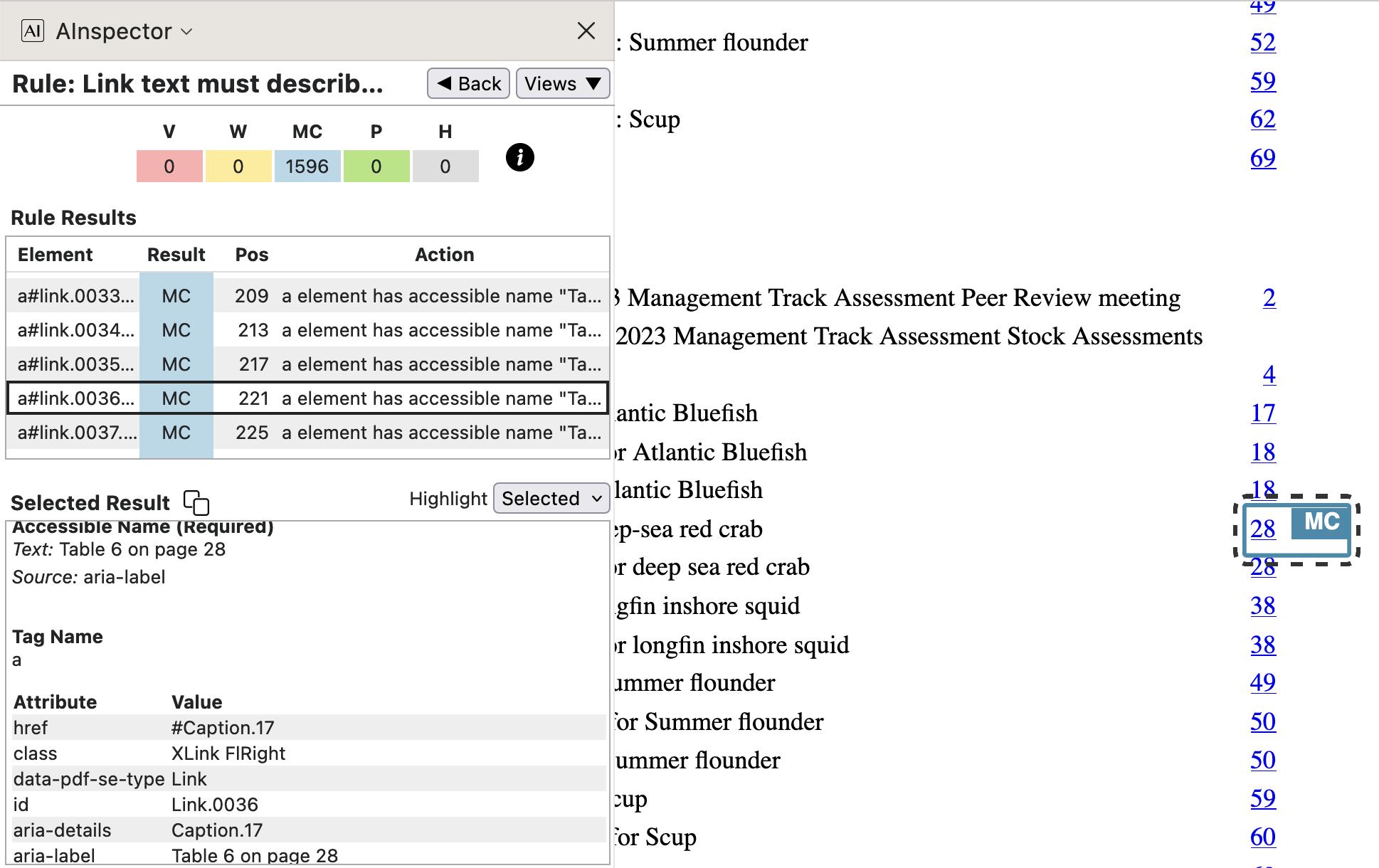
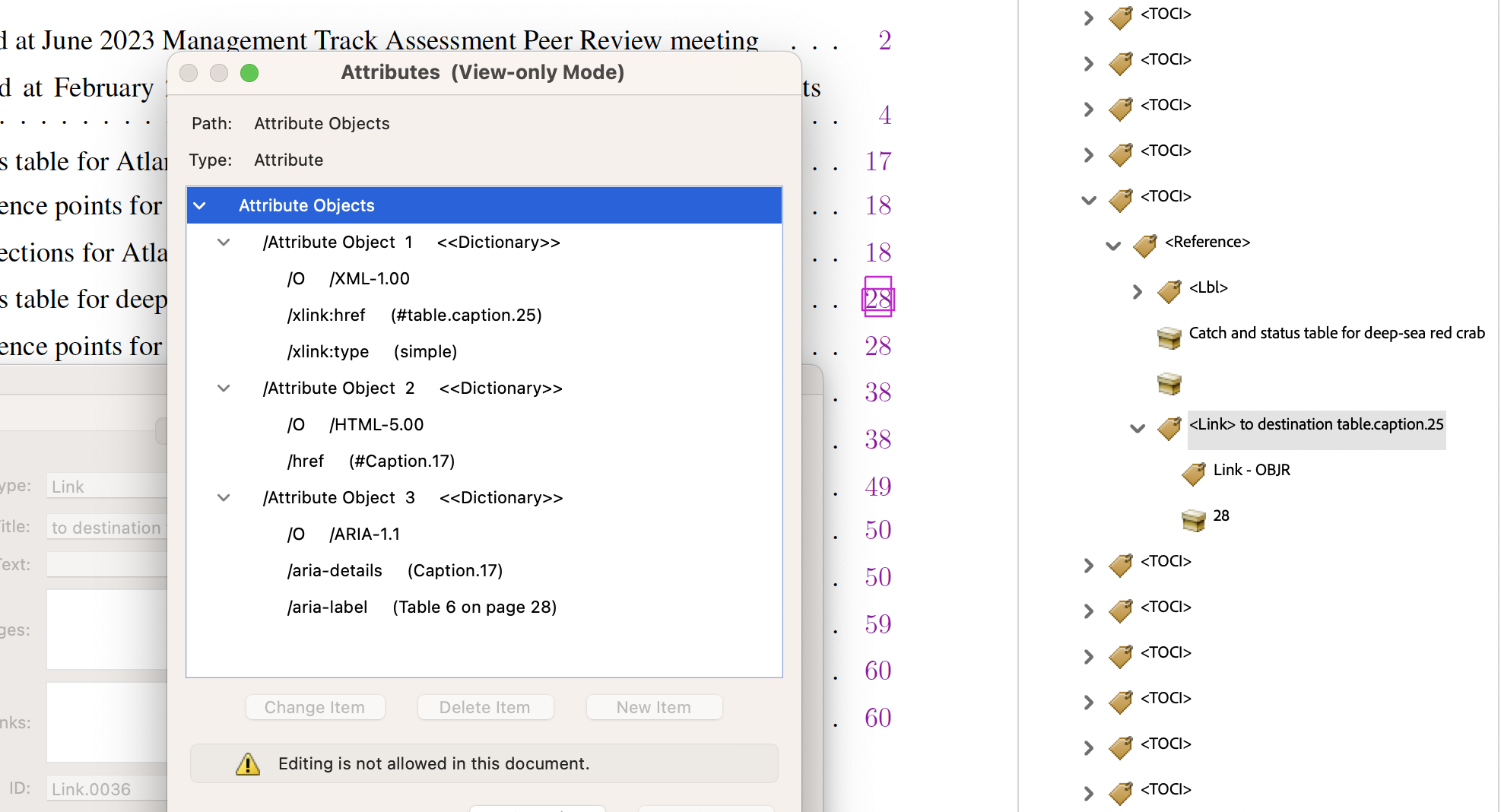
The file
SpringMT2023.lotprovides data for the List of Tables, as in the line shown below. Data there contributes to the attribute values for theLinkstructure.- from
SpringMT2023.lot:\contentsline {table}{\numberline {6}{\ignorespaces Catch and status table for deep-sea red crab}}{41}{table.caption.25}%
- from
SpringMT2023.tgx:\TPDFmakeSD{table.caption.25}{6146}{Caption.17}%
\TPDFtaginfo{6146}{6144}{<Caption>}{Caption.17}{921}{41}{41}%
Here we include also the
\taginfofor the<Caption>structure, in which the the final 3 numbers are used to check consistency of the pagination, with successive LaTeX processing runs. On the previous run, the floating table occured on virtual page 41 (= 28 + 13) having PDF object number 921. The apparent duplication of 41 is for checking that the internally-recorded page number is correct after floating. - from
- Cross-reference to a Table or Figure within the same Section.
Although within a paragraph, a cross-reference uses a user-supplied name; e.g.
, within the LaTeX-generated PDF it is only the internal ‘Named Destination’, and associated ‘Structure Destination’, that is used.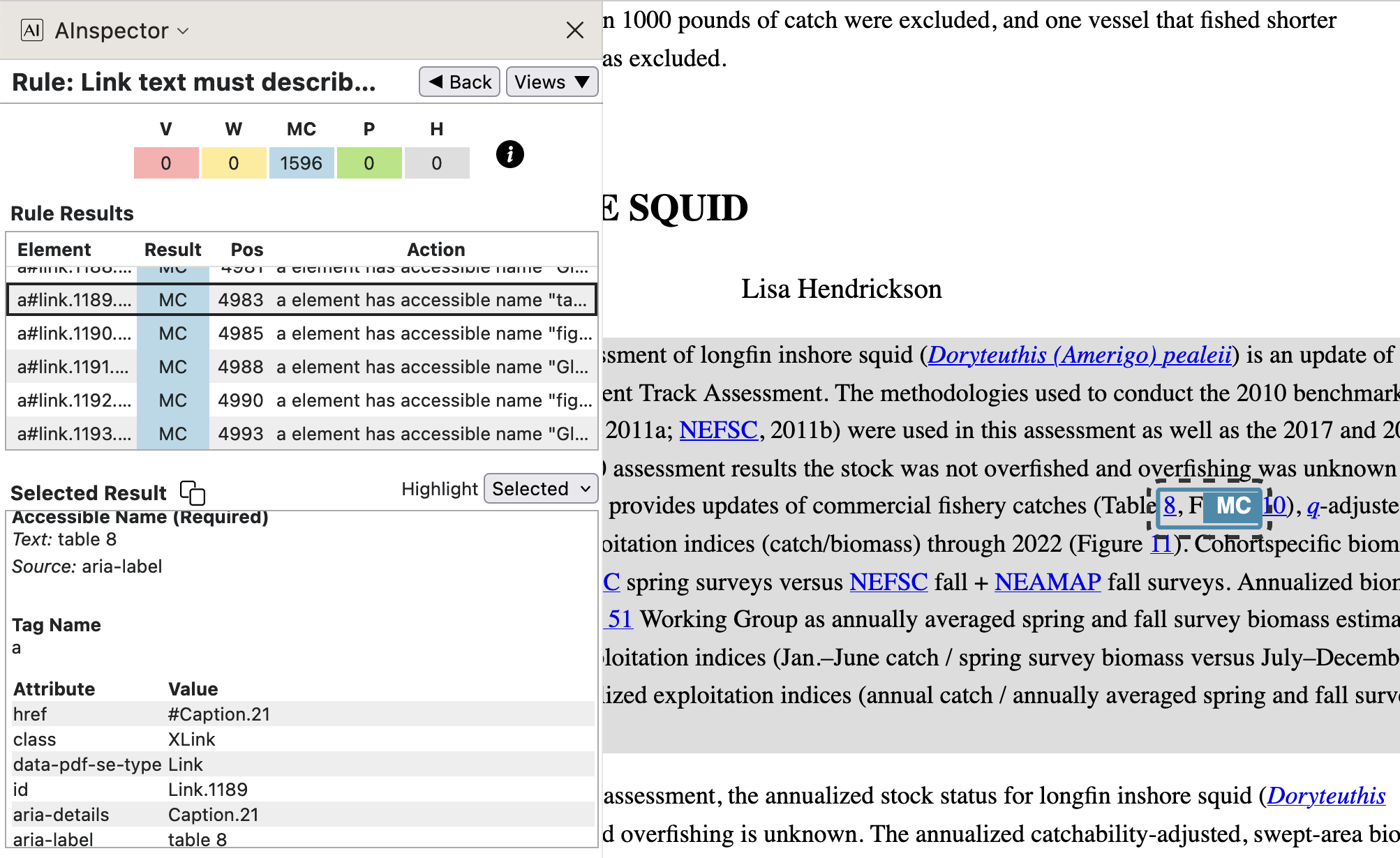
The connection between the user-defined
\label{...}and the internal destination is handled through the auxiliary fileSpringMT2023.aux, using a\newlabelcommand as shown below. The\@writefile{lot}{...}command causes a line to be written into fileSpringMT2023.lot.- from
SpringMT2023.aux:\@writefile{lot}{\contentsline {table}{\numberline {8}{\ignorespaces Catch and status table for longfin inshore squid}}{51}{table.caption.31}\protected@file@percent }
\newlabel{DORYUNITCatch_Status_Table}{{8}{51}{Catch and status table for longfin inshore squid}{table.caption.31}{}} - from
SpringMT2023.tgx:\TPDFmakeSD{table.caption.31}{6759}{Caption.21}%
\TPDFtaginfo{6759}{6754}{}{Caption.21}{1908}{50}{51}%
This time the table float was processed before virtual page 50 was completed, but it floats to virtual page 51 having object number 1908.
- from
- Acronym or Abbreviation, anchors a link to the associated Glossary entry.
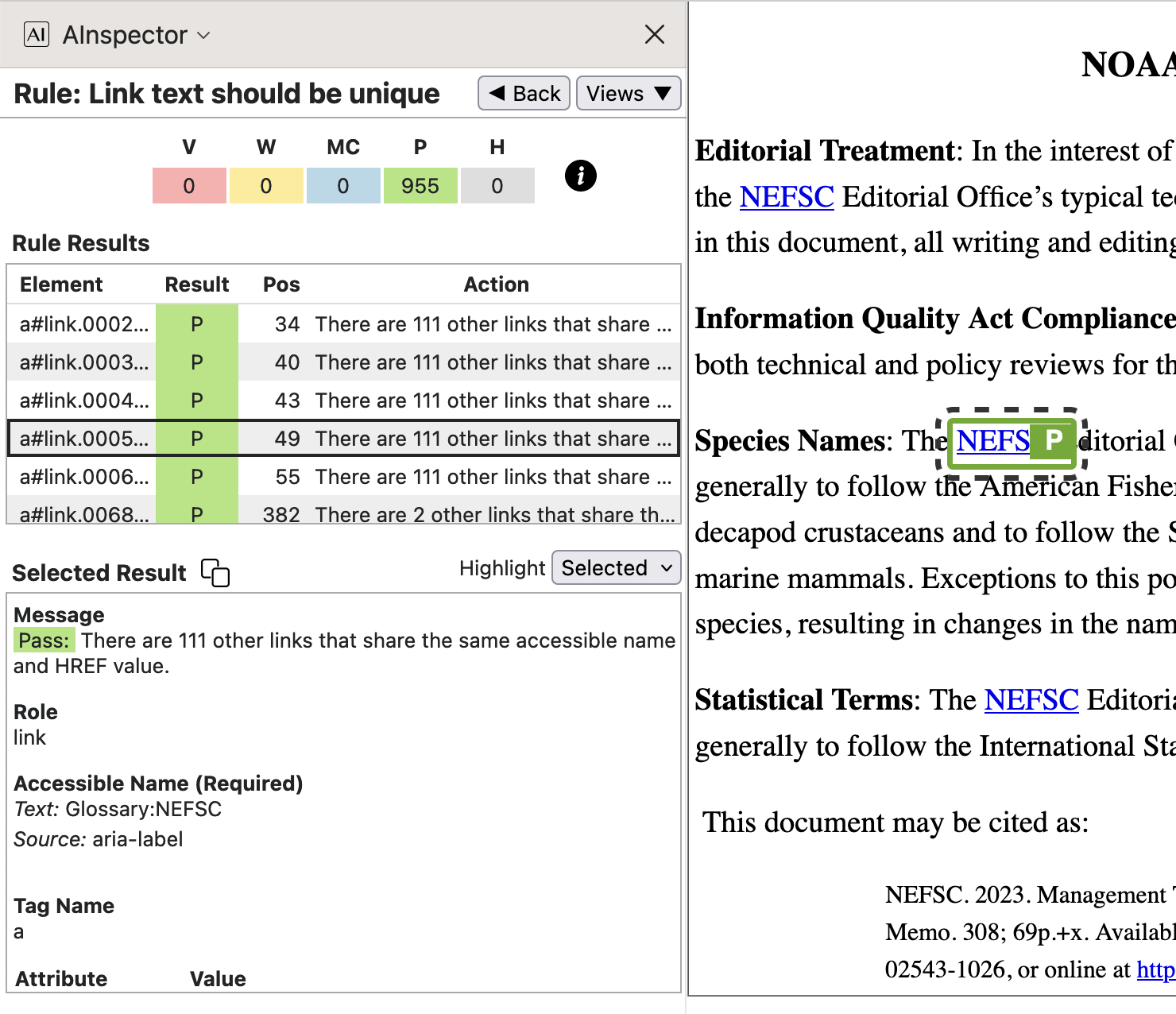
An ‘Accessible Name’ of ‘Glossary:NEFSC’ is provided by the
aria-labelattribute of the hyperlink. Target of the hyperlink is the structure named ‘TOCI.091’, which is derived from a<TOCI>item within a Glossary<TOC>. The ‘Accessible Description’ is the subject of a rule in SC 2.4.6.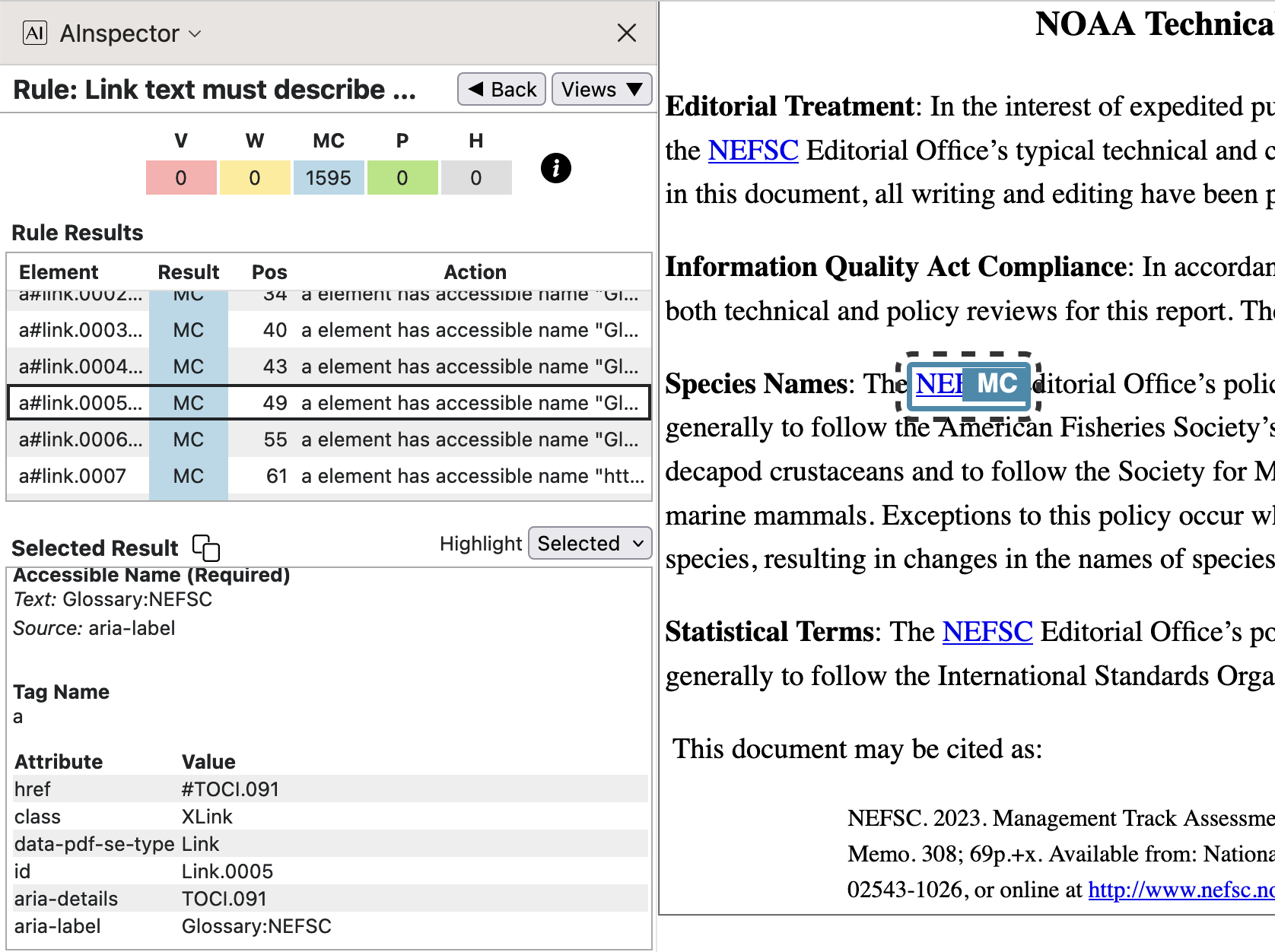
The same ‘Accessible Name’ is created for all links to the same Glossary item, by using a LaTeX macro (in this case
\NEFSC) to construct the link and record the use of an Acronym.- from
CRDacronymFiles.tex:\CRDmakeacronym{NEFSC}{\NEFSC}{NEFSC}{N E F S C }{Northeast Fisheries Science Center}{}
The 6 arguments to
\CRDmakeacronymare used as follows: #1 is the sort key, with #2 being the user-macro to invoke the acronym/abbreviation in the LaTeX source, resulting in #3 being typeset, with #5 to be shown as the description on a Glossary page. The extra parameters #4 and #6 (or #5) are for/Altand/E(Expansion) text in the PDF page contents. If #5 is unsuitable, by having expandable items (active macros), then #6 is used to pass a clean text-only description of the meaning of the abbreviation. Notice that #4 ensures that a screen-reader spells out the acronym, rather than trying to pronounce a poorly-spelt word.
The corresponding portion of the page content stream is shown above, including the colouring, positioning and font-selection commands produced by the pdfTeX processing, as well as the tagging and textual content.
- from
- Statistical variable name (perhaps with subscript, name or math symbol) anchors to a Glossary entry.
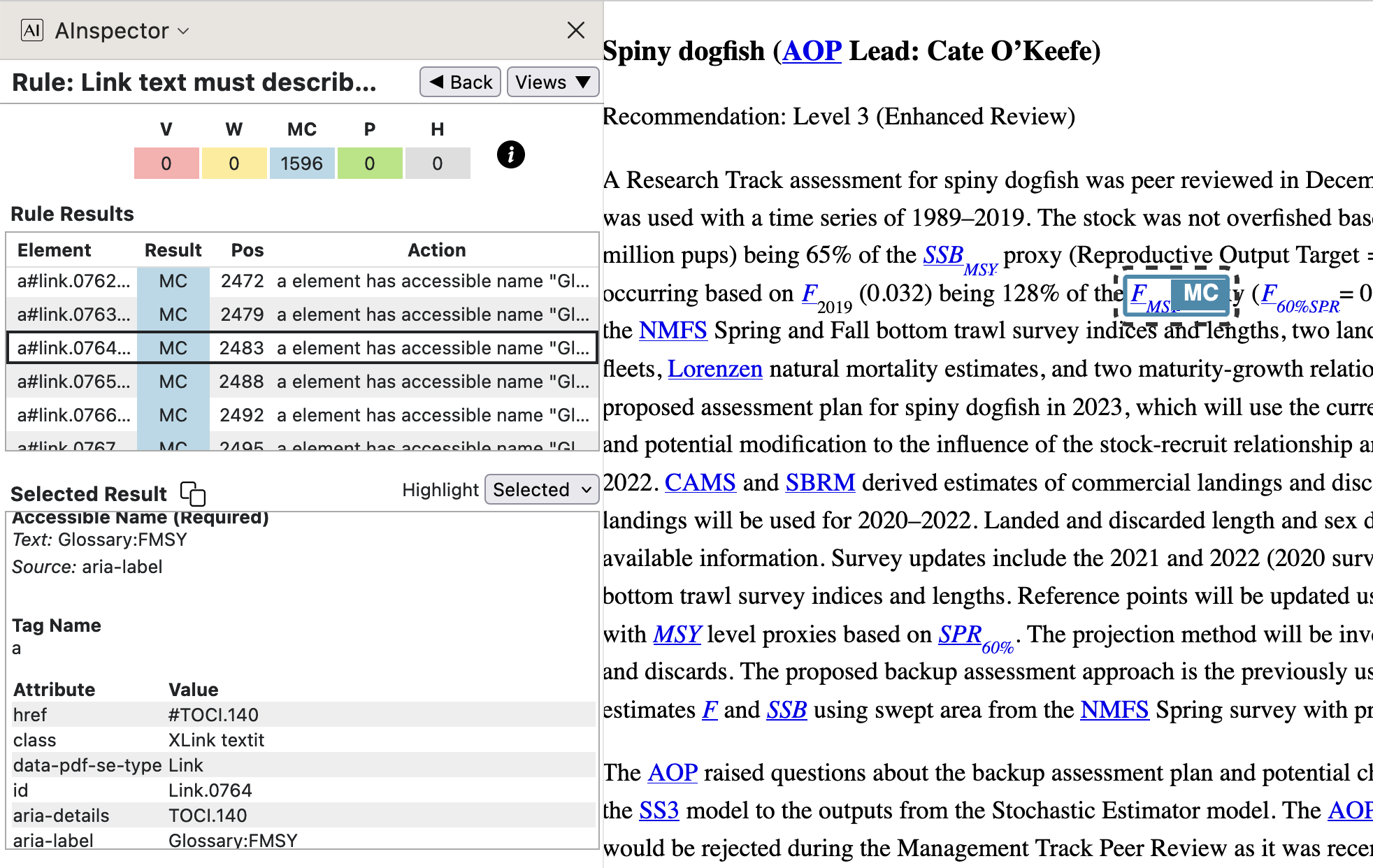
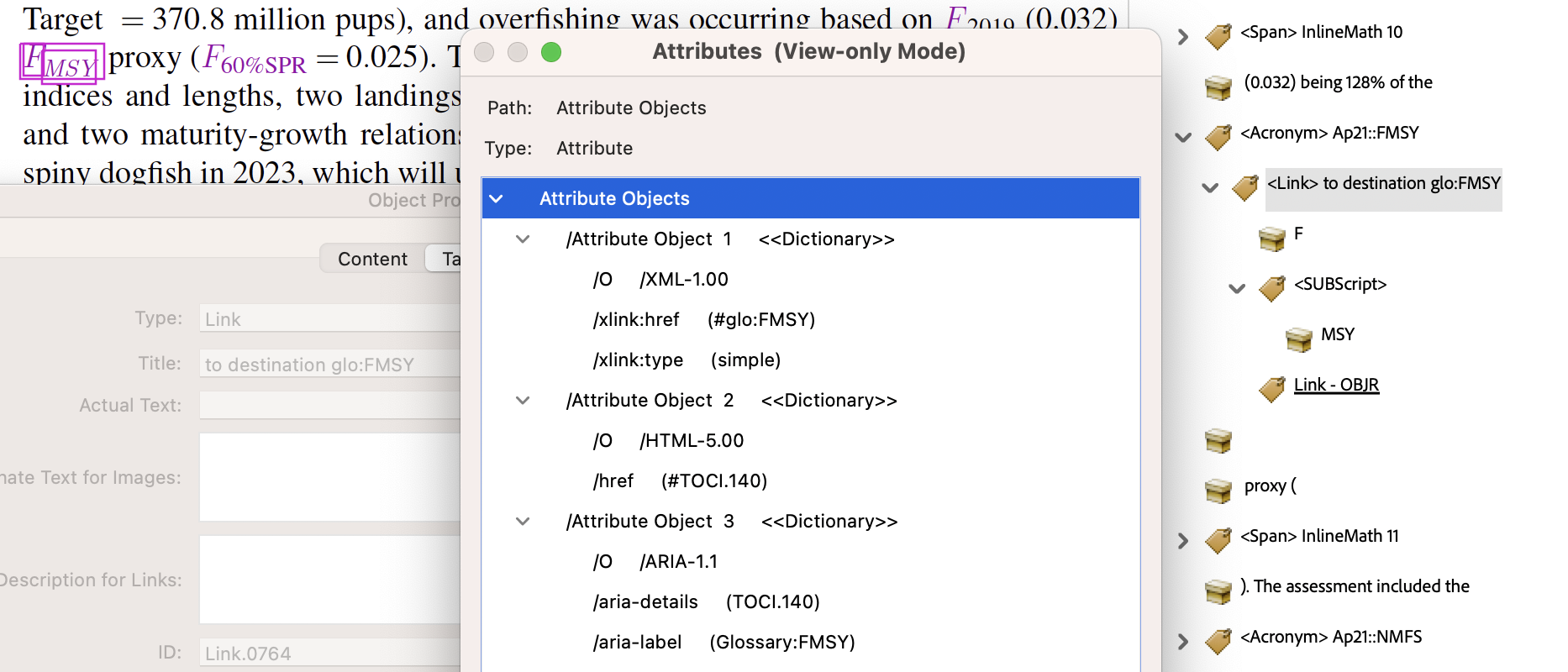
- from
SpringMT2023.tgx:\TPDFmakeSD{Ap21::FMSY}{3885}{Link.0764}%
\TPDFtaginfo{3885}{3870}{<Acronym>}{Acronym.182}{973}{21}{22}%
\TPDFtaginfo{3886}{3885}{<Link>}{Link.0764}{973}{21}{22}%
\TPDFtaginfo{3888}{3886}{<SUBScript>}{SUBScript.040}{973}{21}{22}%
The link for the <Acronym> is named
Link.0764which has a <SUBScript> child. Its target has ‘Accessible Name’Glossary:FMSYand is the Glossary item namedTOCI.140which provides the ‘Accessible Description’. Being the 1st instance of this kind, it also has a ‘Structure Destination’ associated with the ‘Named Destination’ ofAp21::FMSY.Declaring this kind of Acronym having structured expansion is done as follows.
- from
CRDspecialAcronym.tex:\CRDmakespecialacronym
{FMSY}{\FMSY}{\FMSYmath}{F_{\!\!\mathit{MSY}}^{}}{F[M S Y] }%
{fishing mortality rate for maximum sustainable yield}{}
This time there are 7 arguments to the meta-command
\CRDmakespecialacronym, with #1 and #2 same as previously. Now #4 creates the visible text (using math-mode) while #3 gives a macro-name that produces this visible text within a context that doesn't require an Acronym link, should this ever be needed. So #5 is the/Alt-text, with #6 the printable expansion which also serves for the/E(expansion) text with #7 being empty. - from
- Glossary, back-link to where the Glossary entry was used; 1st instance on the stated page.
In this example we have a ‘Named Destination’ of
Ap14::AOPcorresponding to a ‘Structure Destination’ namedLink.0576, which is the 1st (and only) child of an<Acronym>structure. This latter is a Custom structure having a ‘RoleMap’ entry of/Reference, which could potentially have more sub-structure than a singleLink.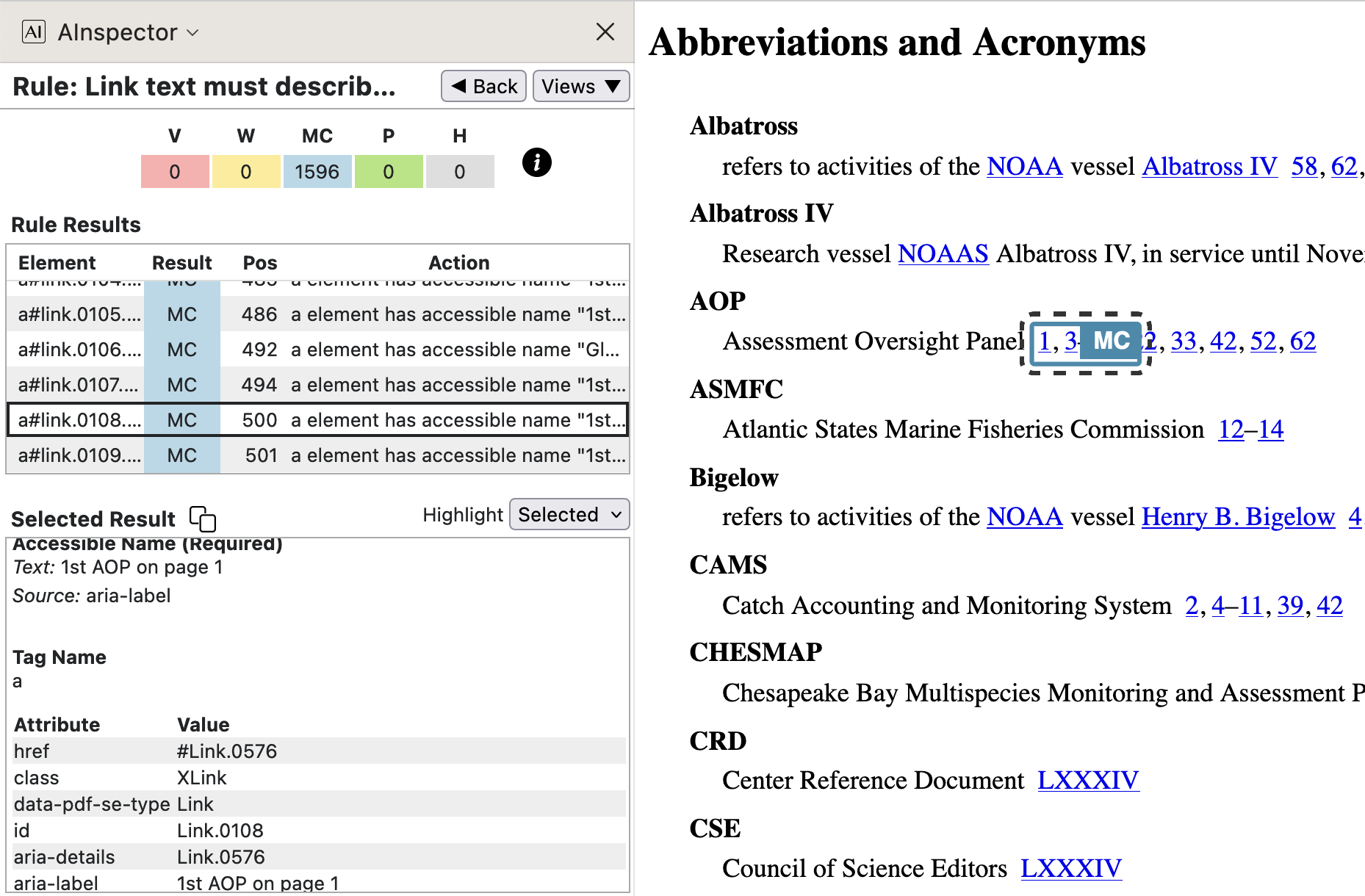
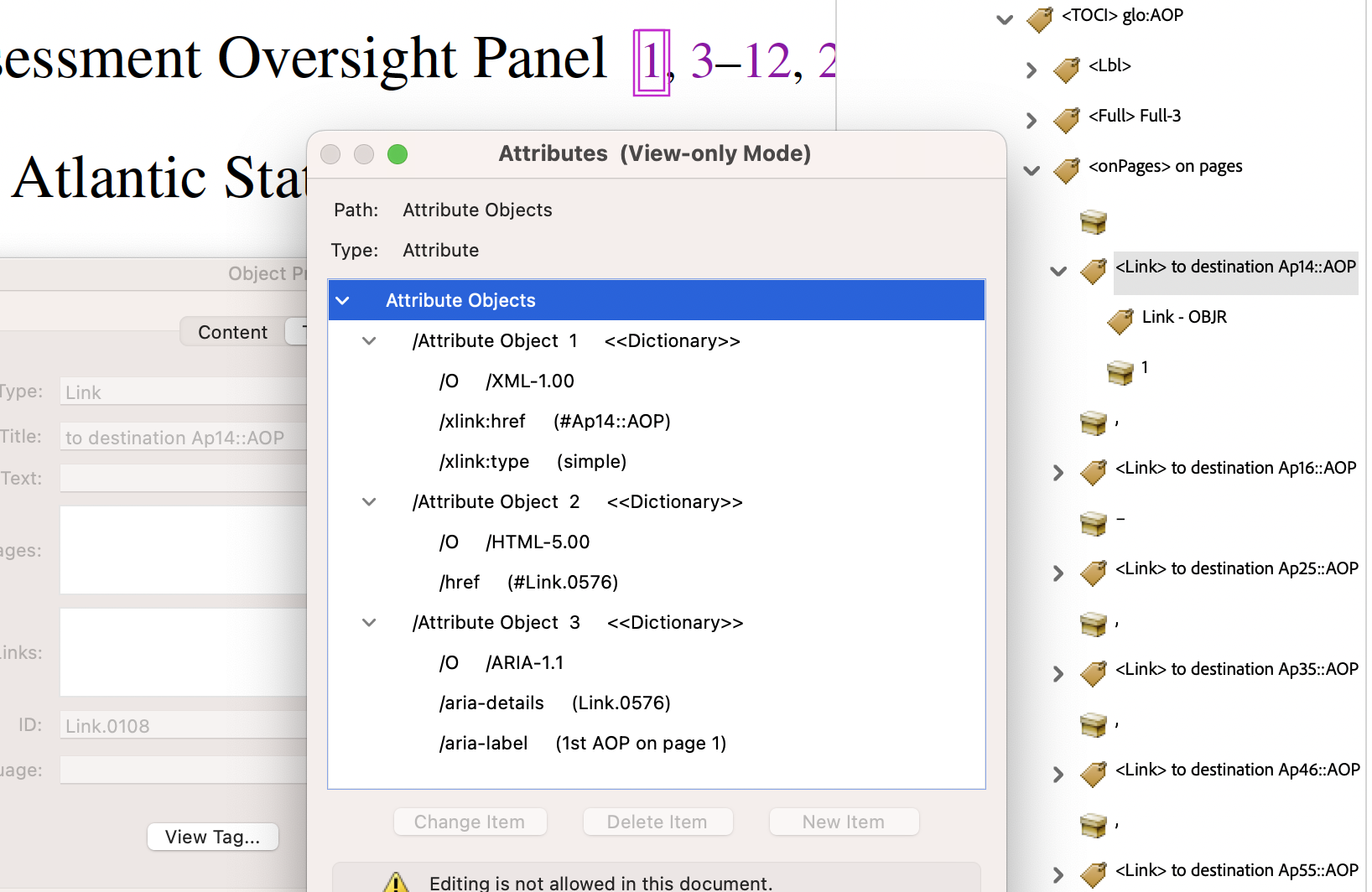
- from
SpringMT2023.gls:\glossentry{AOP}{\glossaryentrynumbers{\relax
\setentrycounter[]{page}\glsnumberformat{14}\delimN
\setentrycounter[]{page}\glsnumberformat{16\delimR 25}\delimN
\setentrycounter[]{page}\glsnumberformat{35}\delimN
...
\setentrycounter[]{page}\glsnumberformat{75}}}% - from
SpringMT2023.tgx:\TPDFmakeSD{Ap14::AOP}{2920}{Link.0576}%
\TPDFtaginfo{2920}{2905}{}{Acronym.006}{2861}{14}{14}%
\TPDFtaginfo{2921}{2920}{}{Link.0576}{2861}{14}{14}%
The string
Ap14signifies the 1st Acronym on page 14, with keyAOPappended to denote the specific Acronym. This is stated explicitly in thearia-labelof the link. Now 14 = 13 + 1, so the visible page-number of ‘1’ appears as the anchor-text, being the 1st main-matter page following the 13 pages of Cover and front-matter. From the 2nd\taginfoline above, we see that the object numbered 2921, named asLink.0576, has the object numbered 2920 as parent. This parent is namedAcronym.006, being the 6th usage of an Acronym outside of the Glossary itself. Thus the ‘Structure Destination’ information in the PDF leads to an appropriate link also in the HTML.Even the punctuation invoked by
\delimNis treated specially in the PDF content stream, getting/Alttext of ‘ and ’ for screen-reading. Similarly\delimRgets/Alttext of ‘ up to ’ within a number range. The whole line, including the explanation, is spoken as:; Glossary-item ; ; AOP ; Assessment Oversight Panel ; occurs on page: ; 1 and 3 up to 12
and 22 and 33 and 42 and 52 and 62Here the nature of the information following is stated first, with each ‘;’ contributing a slight pause. The otherwise ambiguous uses of ‘,’ (comma) and ‘–’ (the
endashcharacter) have been replaced by their semantic meaning within this context. Be aware that the PAC 2024 validator, under the ‘Quality’ panel, flags each of these/Altusages as potentially in error. Yet this is clearly intended as an enhancement of the accessibility for screen-reading. - from
- Footnote marker, as link to footnote text.
On a PDF page the footnote text appears at the bottom of the page. Within HTML there is no such (convenient ?) location. With the structural tagging of the note coming after that of the in-text marker, a convenient layout can be achieved in the HTML using a CSS rule to float the footnote text (at reduced size) to the right, as seen in the image at left below. It is useful in both PDF and HTML to have a hyperlink connecting the marker to the footnote text.
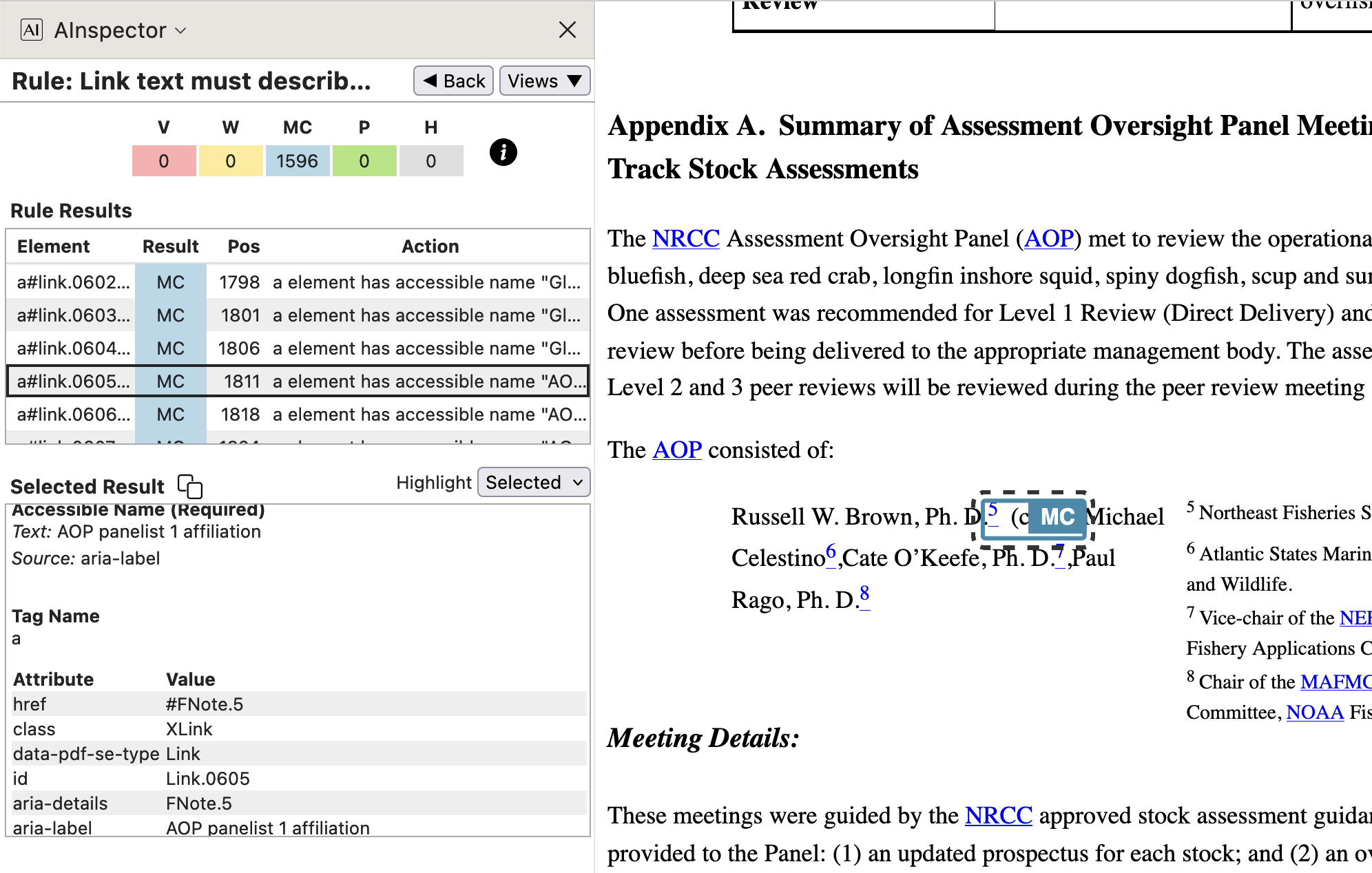
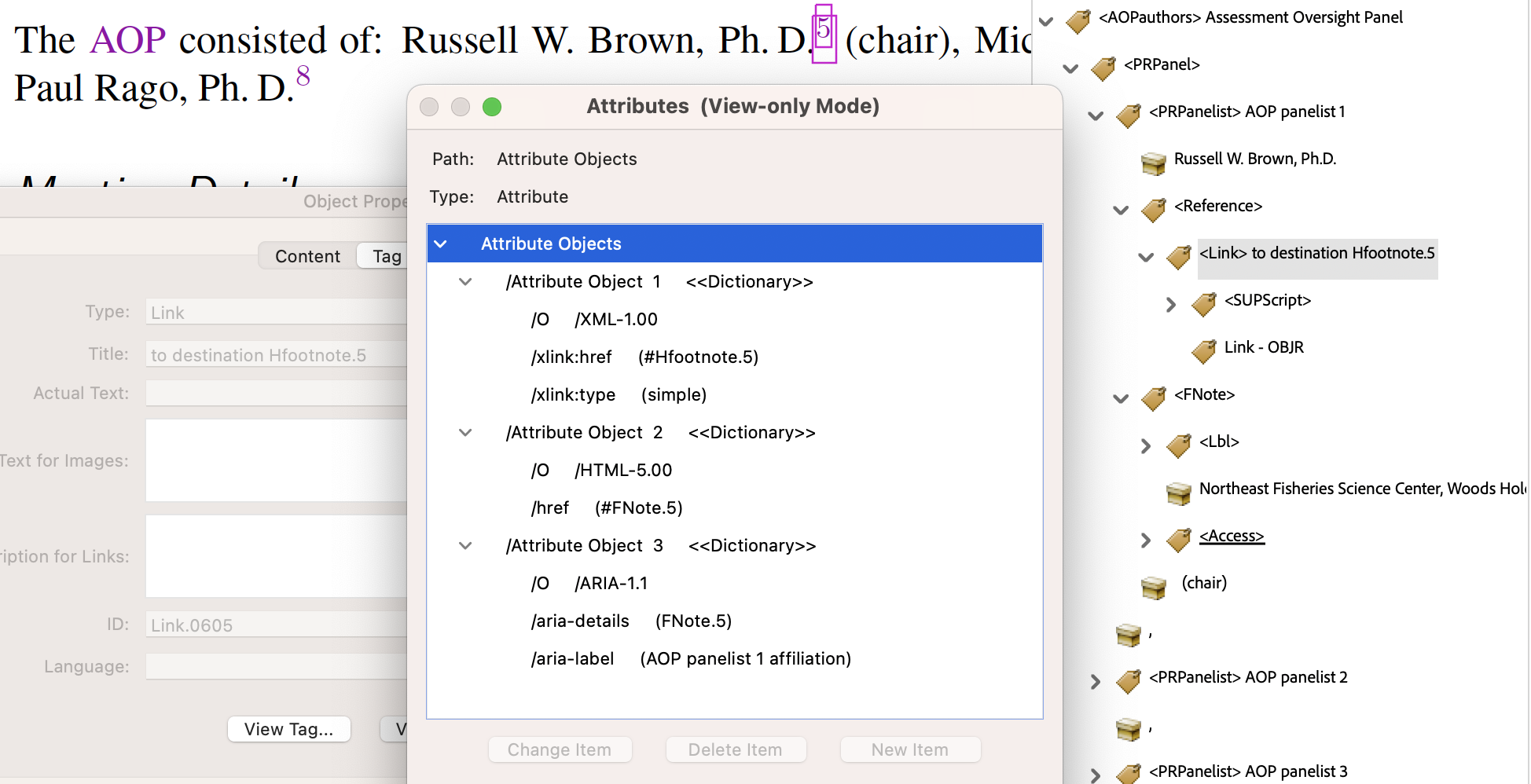
- from
SpringMT2023.tgx:\TPDFmakeSD{Hfootnote.5}{3127}{FNote.5}%
\TPDFtaginfo{3121}{3118}{<PRPanel>}{PRPanel.1}{3102}{16}{16}%
\TPDFtaginfo{3122}{3121}{<PRPanelist>}{PRPanelist.5}{3102}{16}{16}%
\TPDFtaginfo{3123}{3122}{<Reference>}{Reference.082}{3102}{16}{16}%
\TPDFtaginfo{3124}{3123}{<Link>}{Link.0605}{3102}{16}{16}%
\TPDFtaginfo{3126}{3124}{<SUPScript>}{SUPScript.5}{3102}{16}{16}%
\TPDFtaginfo{3127}{3122}{<FNote>}{FNote.5}{3102}{16}{16}%
The lines above from
SpringMT2023.tgxshow how the<Link>namedLink.0605fits into the<PRPanel>structure, with its anchor-text inside a<SUPScript>. The target<FNote>follows immediately afterwards in the structure tree. A ‘Named Destination’ ofHfootnote.5corresponds to a ‘Structure Destination’ for this structure namedFNote.5. - from
- Latin-text of a fish species' name, anchors a link to small image on the fish-stock Glossary page.
The aim of the next link is to provide access to a picture and name of a fished stock species, given its formal latin name. Only experts in the field would use that latin name, so having a link to something more commonly used is natural, and similar to a Glossary link in intent.
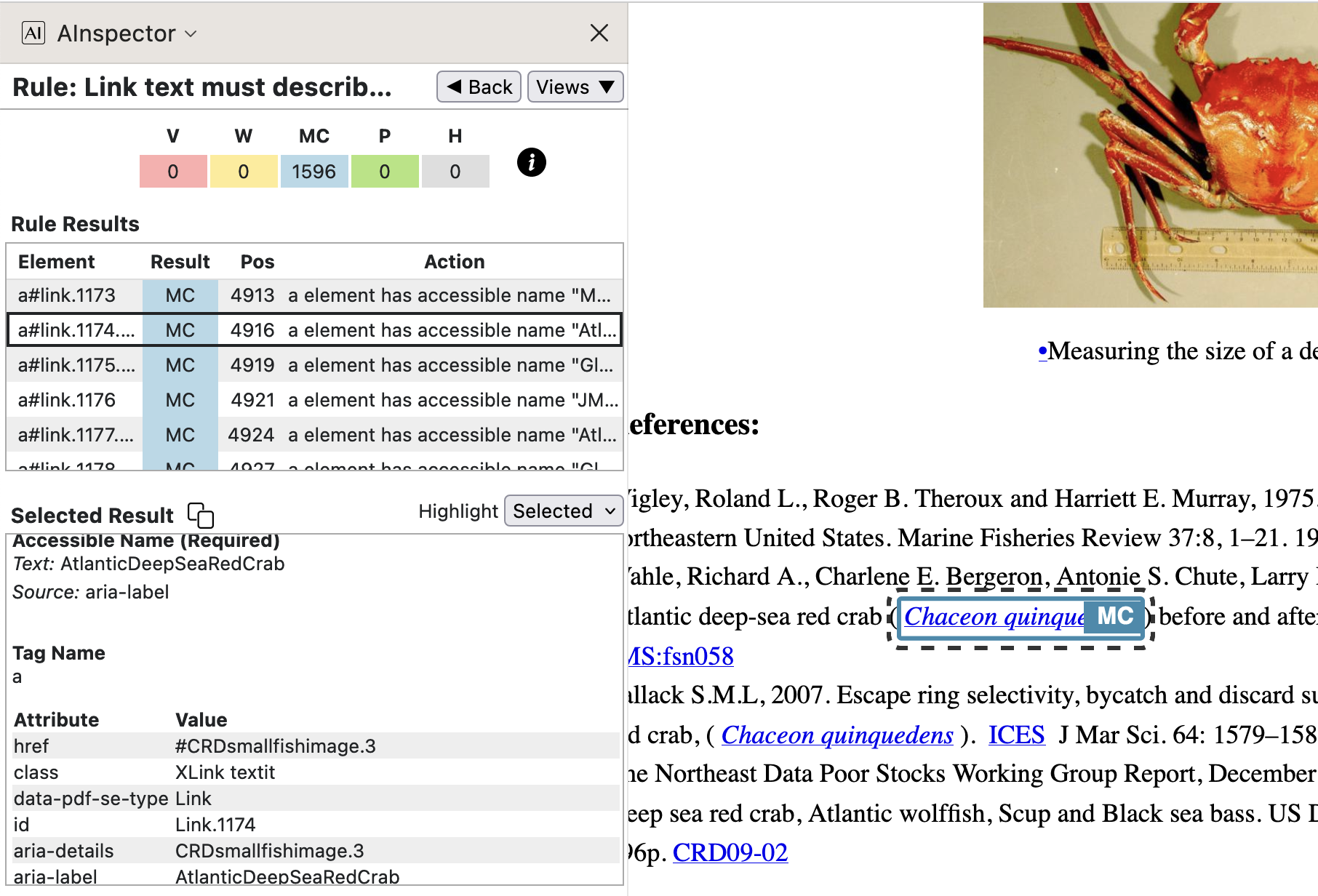
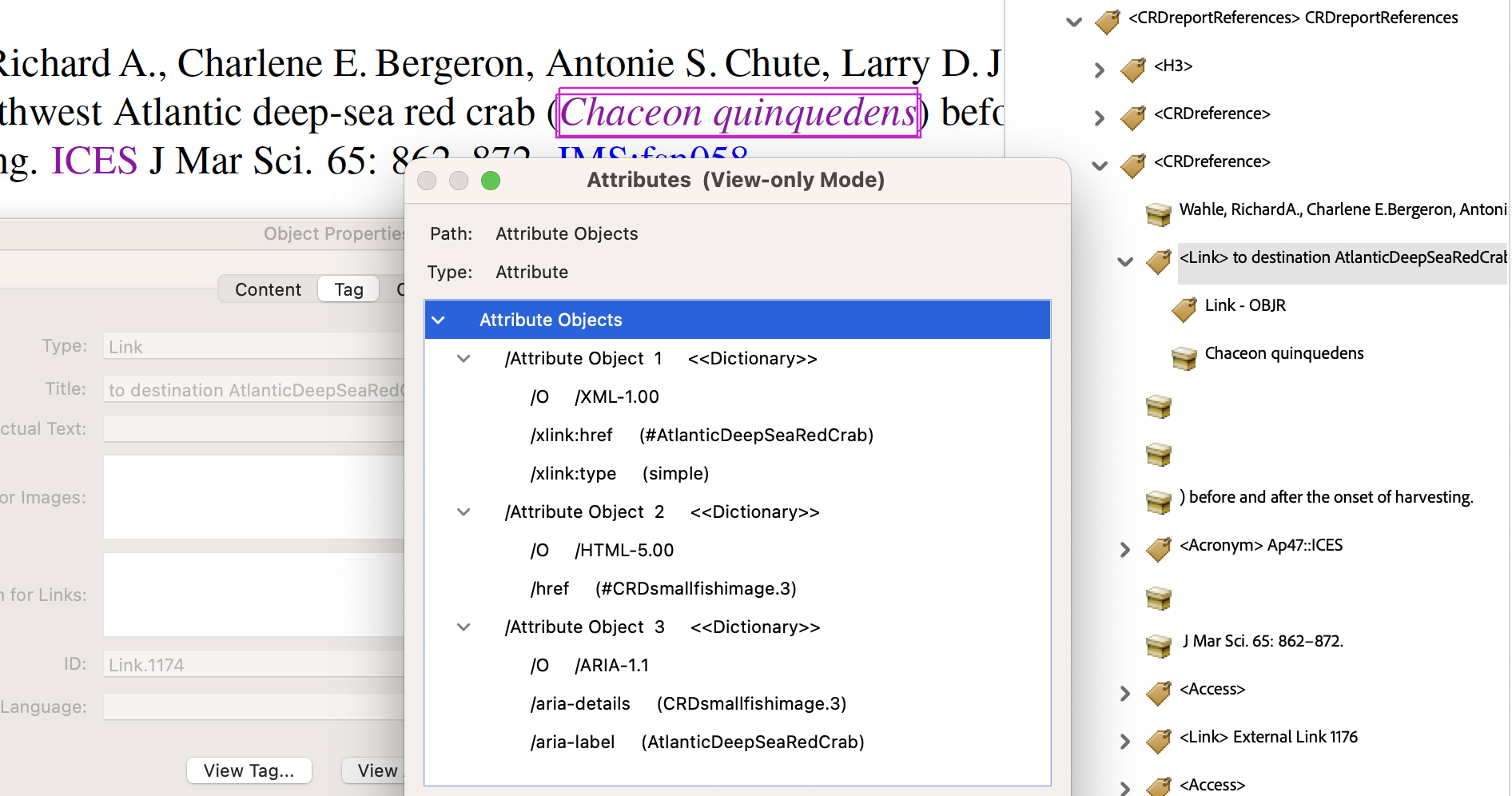
- from
SpringMT2023.tgx:\TPDFmakeSD{AtlanticDeepSeaRedCrab}{828}{CRDsmallfishimage.3}%
\TPDFtaginfo{6561}{6552}{<CRDreference>}{CRDreference.03}{6543}{47}{47}%
\TPDFtaginfo{6562}{6561}{<Link>}{Link.1174}{6543}{47}{47}%
\TPDFtaginfo{828}{814}{<CRDsmallfishimage>}{CRDsmallfishimage.3}{809}{7}{7}%
\TPDFtaginfo{830}{828}{<Fig>}{Fig.05}{809}{7}{7}%
\TPDFtaginfo{832}{828}{<CRDfishname>}{CRDfishname.3}{809}{7}{7}%
In the code lines above we see how the ‘Named Destination’ of
AtlanticDeepSeaRedCrabis related to the Custom structure namedCRDsmallfishimage.3, which includes a<Fig>for an image, along with its labelling caption. This target location can be seen in the ‘pop-up’ in the image below, when the mouse is hovered over the<Link>namedCRDfishname.3when using specific PDF browser software running under a MacOS system.
This image above shows how the intent of the ‘Accessible Description’ can be achieved, but in a fully visual setting. Some PDF viewing software under MacOS has the feature that when the mouse is hovered over the anchor for an internal hyperlink, a small-sized view of the PDF around the destination is produced and ‘pops up’. Focus remains, with the pop-up going away upon moving the mouse sufficiently.
- from
- 2.4.4 ‘Link text must describe the link target’ with external links
With external link targets the ‘Accessible Name’ is based primarily on the anchor text. However an ‘Accessible Description’ may be possible using text elsewhere in the document.
- Link to a journal article, available online
Academic journals have commonly used Acronym-like abbreviations, well known to researchers in the field. Here the anchor-text of the external link incorporates this abbreviation along with an identifying string for the article itself at the journal's own website.
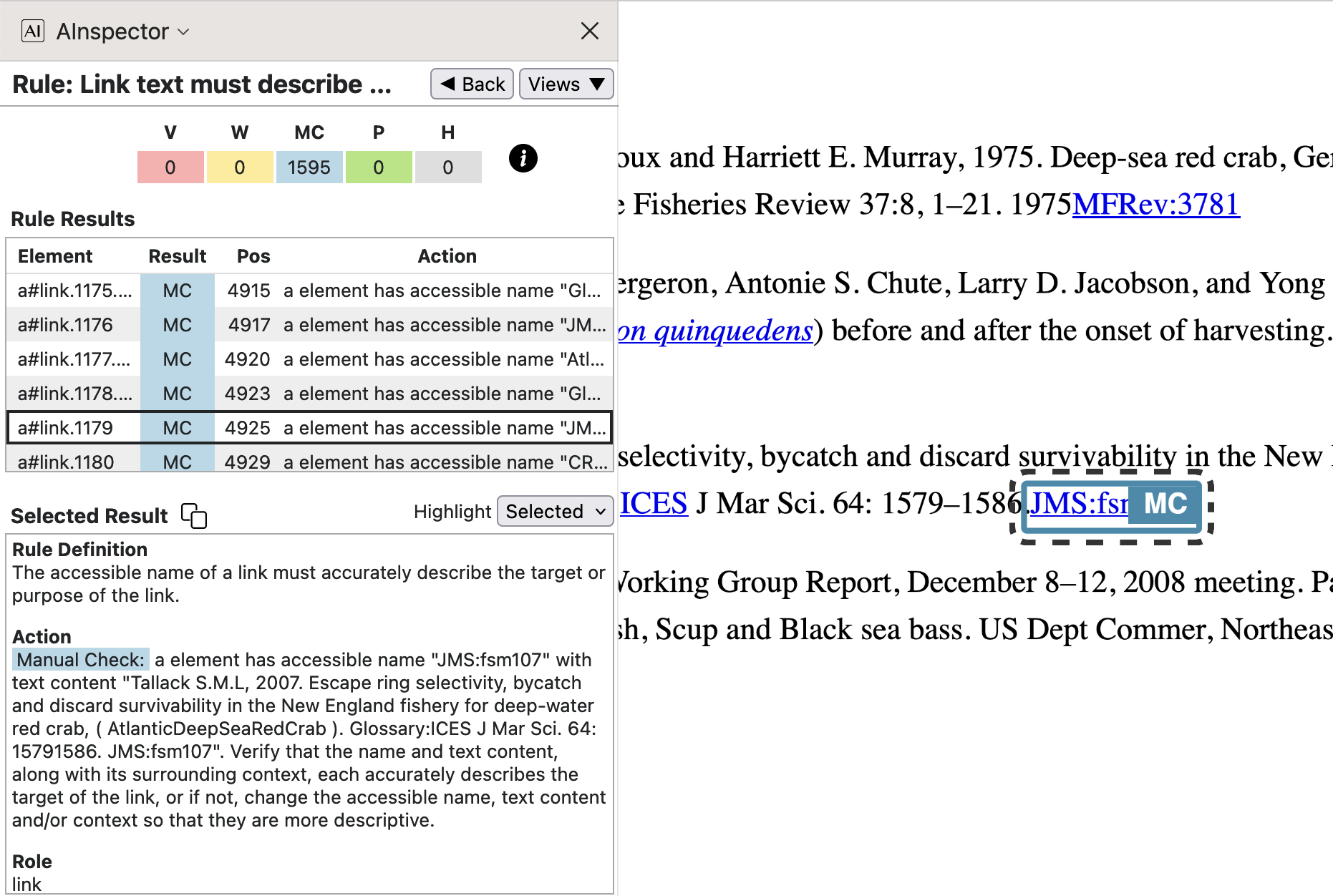
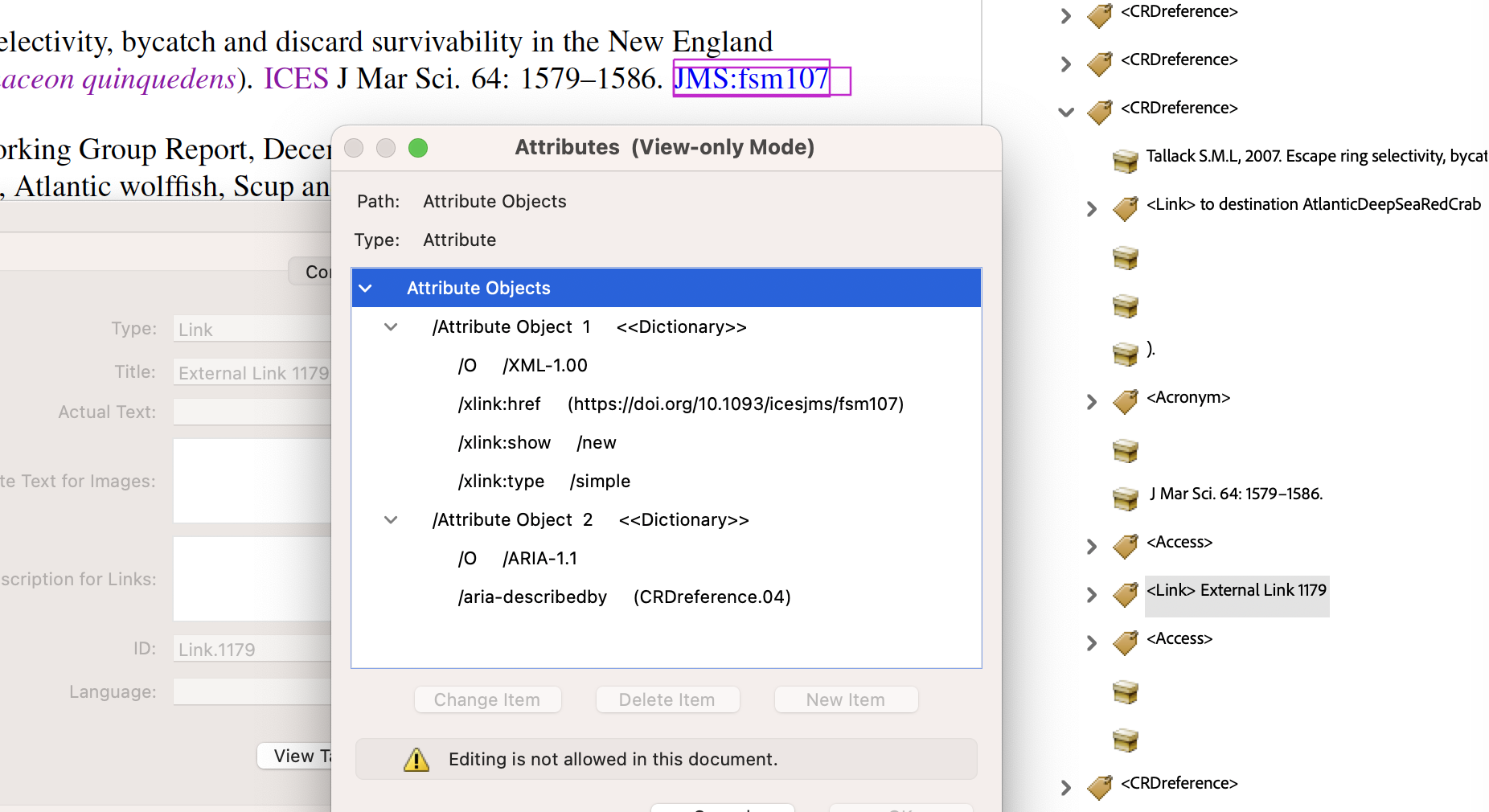
In the above images we see that the target ‘Journal of Marine Science’ is abbreviated to ‘JMS’, and the article identifier used there is ‘fsm107’. So the anchor text has these combined into ‘JMS:fsm107' for the ‘Accessible Name’. Using an
aria-labelledbyattribute the full bibliographic entry is picked up as the ‘Accessible Description’. In the PDF this entry content for a Custom structure of type<CRDreference>, namedCRDreference.04. With PDF 1.7 this custom type has a ‘RoleMap’ entry of/P; this will become/BibItemin future when using PDF 2.0 as the underlying PDF standard. - External link using the full URL
When the anchor text is a full URL then ‘Accessible Name’ is this web-address. It is likely to be as meaningful to a visually-impaired person, as it is to someone fully-sighted. Any choice of whether to follow this link will be based upon context.
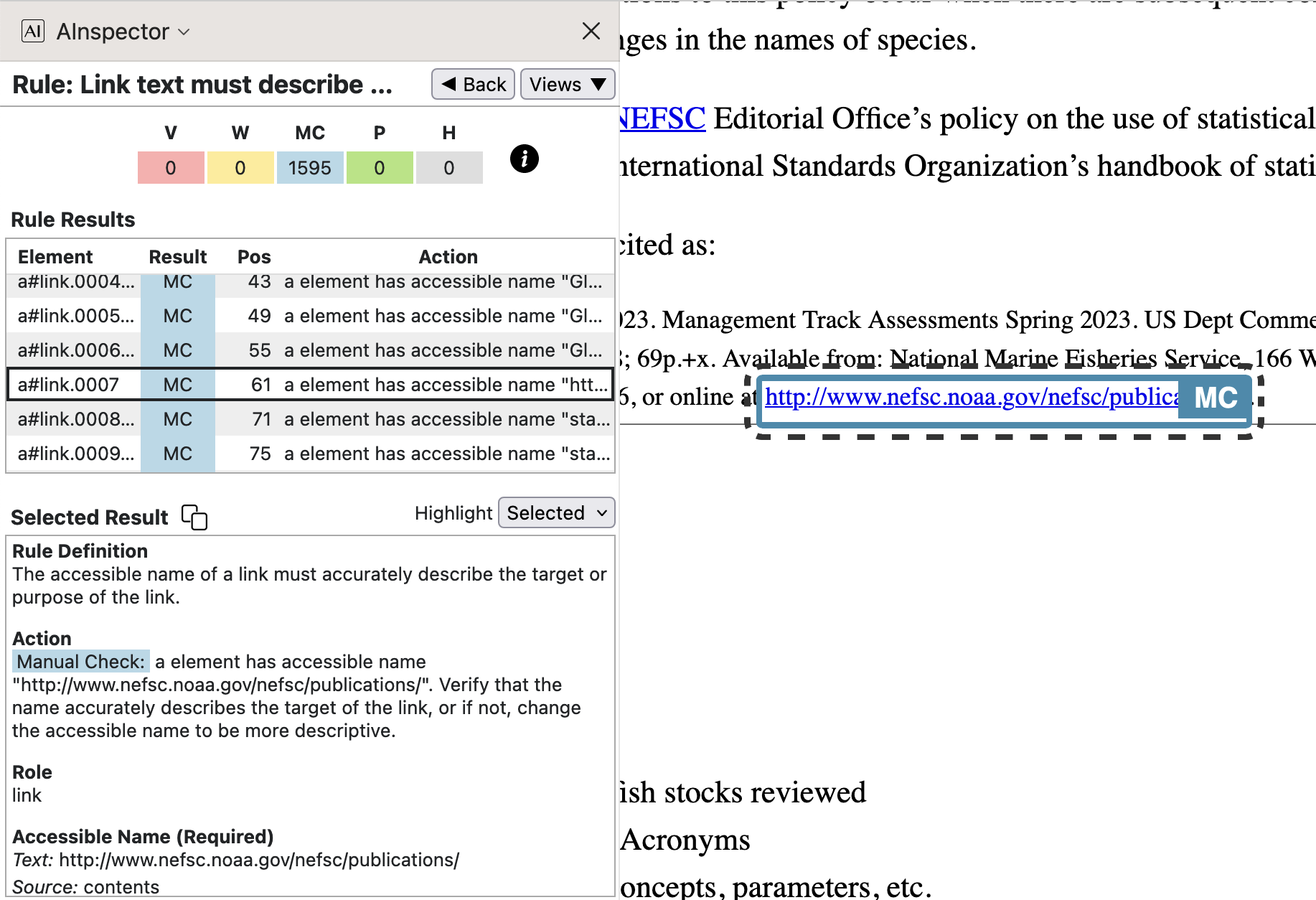
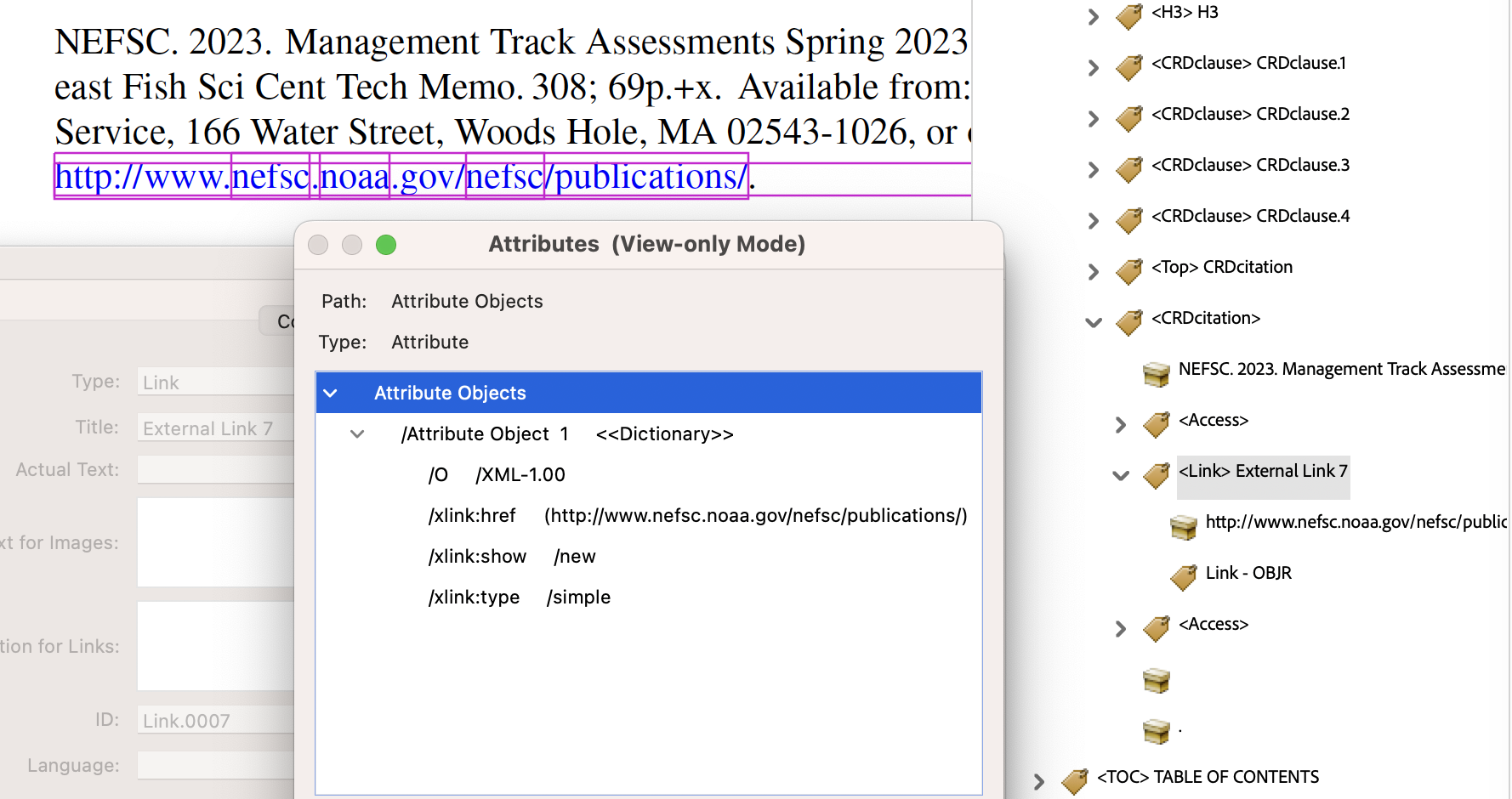
In this case the text of the URL has an associated
/Alt-text replacement, to ensure that it is read properly by AT that detects and uses this attribute.; link to ; http://www.n e f s c.n o a a.gov/n e f s c/publications/
- Link to a journal article, available online
- 2.4.5 ‘At least two ways of finding content‘
Both the PDF and its derived HTML have multiple ways to navigate to specific content. Apart from scrolling, and page-up/down buttons in a PDF browser, there are collections of hyperlinks as follows.
- Table of Contents, navigating via sections, subsections, etc.
- List of Tables, with 2 or 3 tables in each main section.
- List of Figures, navigating to graphs and charts at the end of each fish-stock report section.
-
4 Glossary sections in the front-matter part of the document, each having back-links to where
an acronym or abbreviation has been used. These are organised for specific kinds of information.
- Abbreviations for fish stocks reviewed
- Abbreviations and Acronyms
- Statistical/review concepts, parameters, etc.
- Locations/regions: state, country, etc.
- Photo Gallery, with links to photos and illustrations occuring throughout the whole document. Each main section has at least one such photo or illustration. This is implemented as a 5th Glossary, linked-to from each photo's caption, and with a back-link to where it occurs.
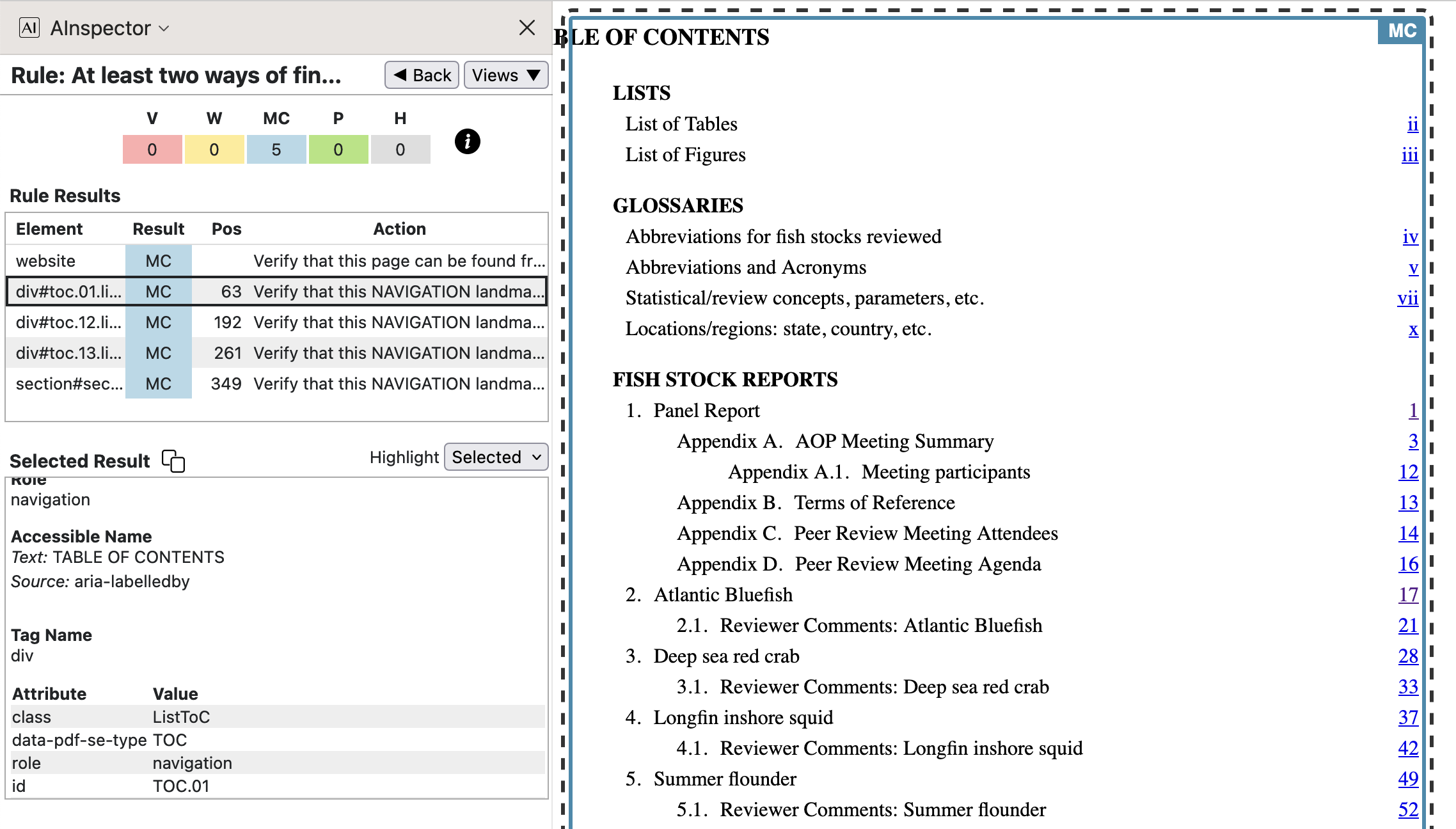
The first 4 of the bulleted structures is in a section with ARIA
role='navigation', so becomes a ‘Landmark’. Verifying that this is appropriate is what the MC is about, in the image above, for the latter 4 instances. - 2.4.6 ‘Provide list labels when appropriate‘
In the following image, the sublist in the ‘Table of Contents’ gets an
aria-labelledbyattribute. In the PDF this refers to the contents of a<Caption>structure, 1st child of a<TOC>.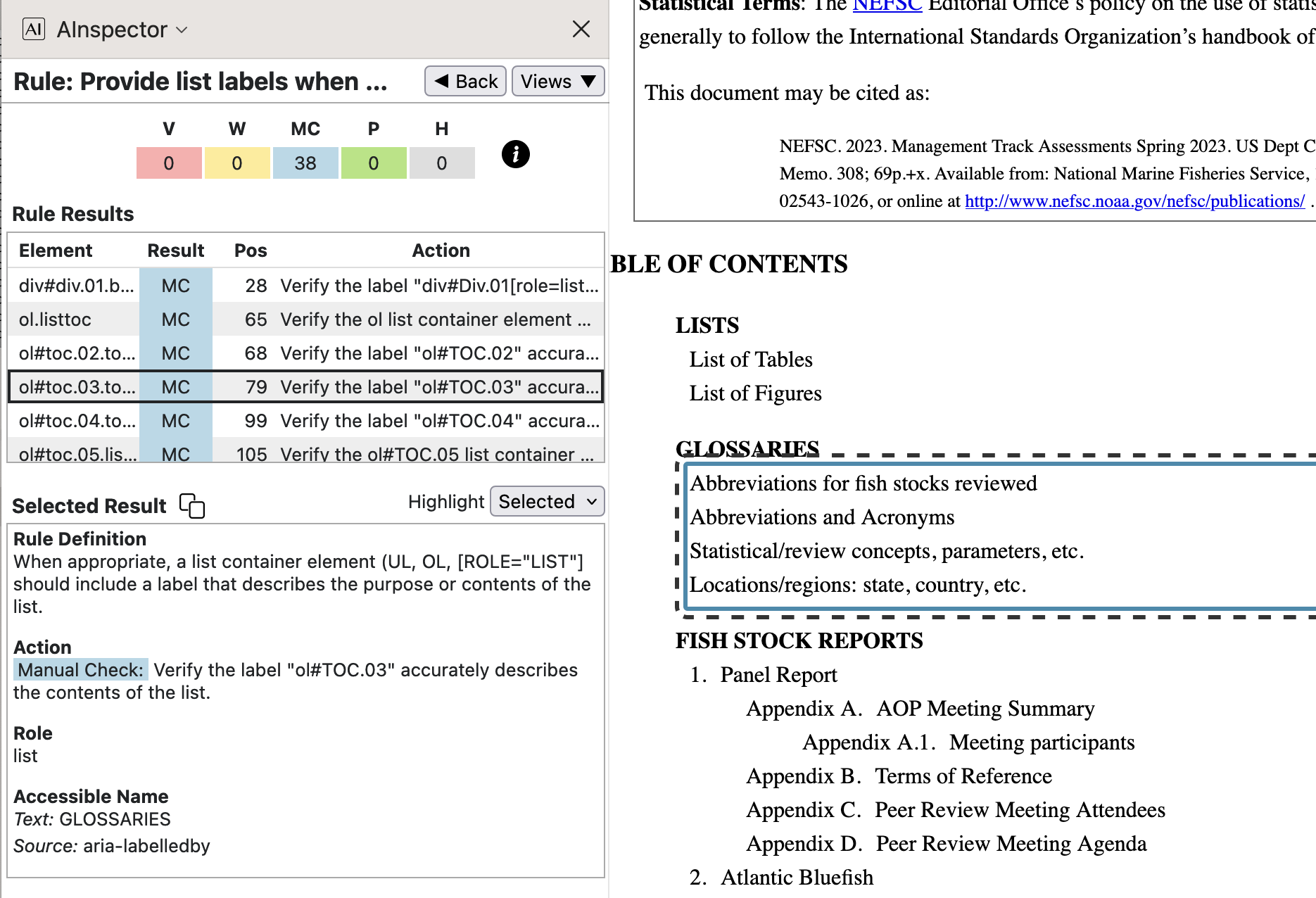
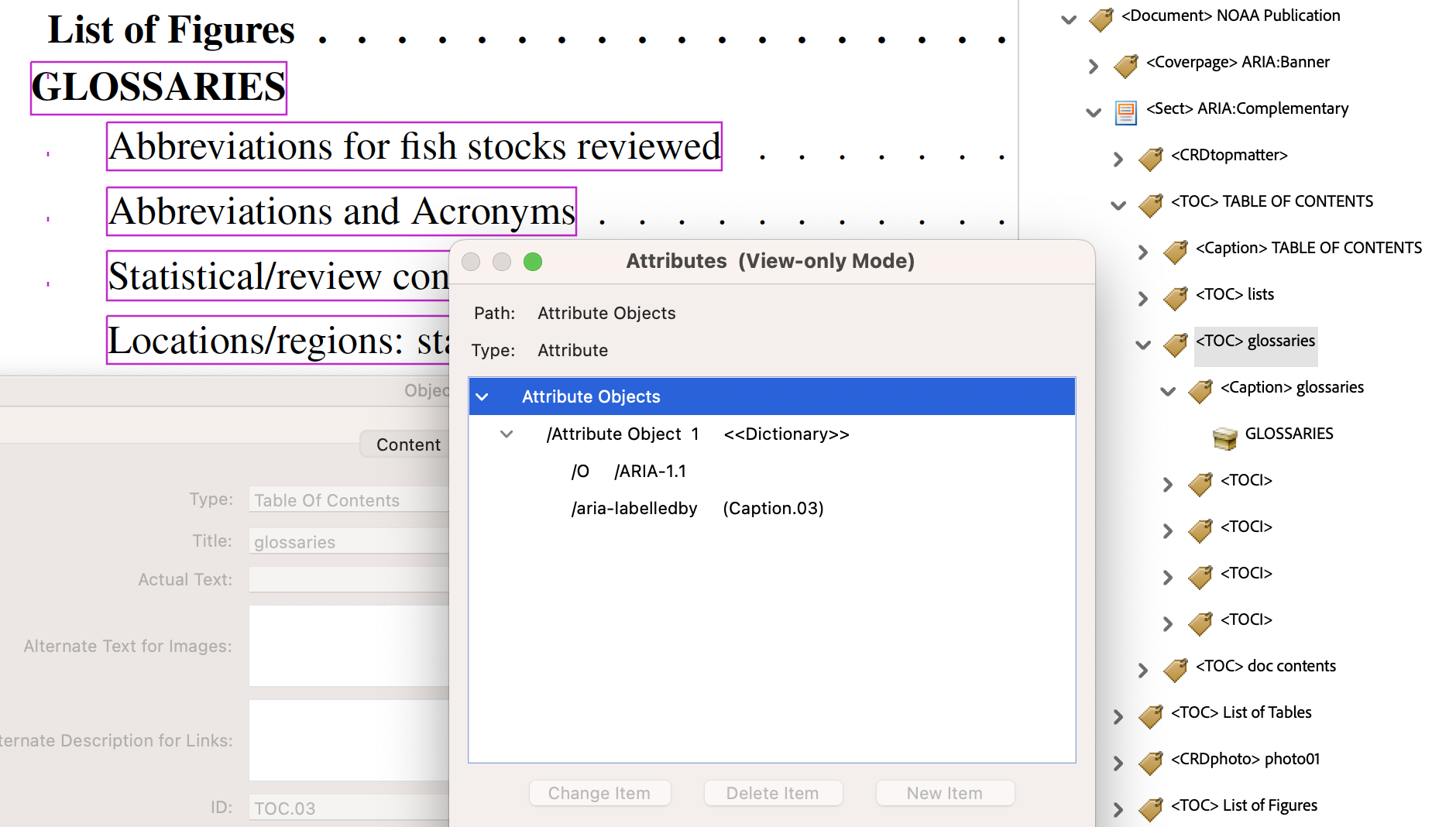
In the derived HTML, the
<p>resulting from the<Caption>structure must be moved to outside (i.e., before) the<ol>, as only<li>is allowed as a child. This explains why the selection in the HTML image does not include the word ‘GLOSSARIES’, whereas it does in the PDF view. Each of the 38 lists can be checked to have an ‘Accessible Name’ obtained from aaria-labelledbyattribute. (Note that strings such asol#TOC.03are in error in the AInspector panel. This is a tag name, displayed in place of the intended name, which is given further down.) - 2.4.6 ‘Accessible name is descriptive‘
With Glossary-item links, the ‘Accessible Name’ for the target is constructed as ‘
Glossary:’ followed by the database key used for the glossary item. Typically for an acronym or abbreviation this is just the short version itself. Hence we getGlossary:NEFSCin the example shown in the image below.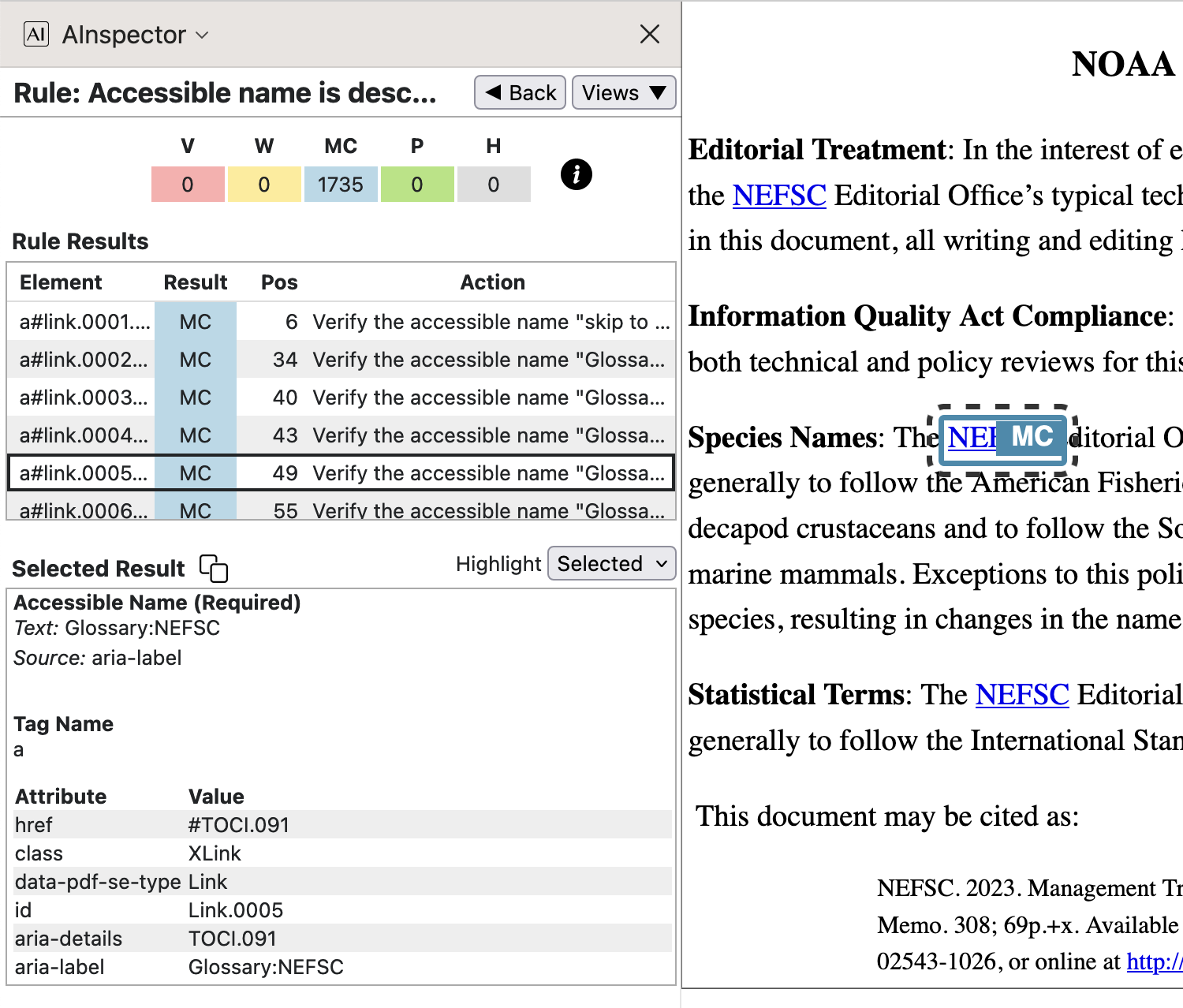
Having simply recognisable keys is part of the way the Glossary items are specified, for ease of use by report authors. It follows that the resulting Accessible names will be descriptive as a matter of course. For other kinds of links, check the images provided above, under SC 2.4.4; in all cases the names are built algorithmically using identifiers relevant to the target destination.
- 2.4.7 ‘Focus must be visible‘
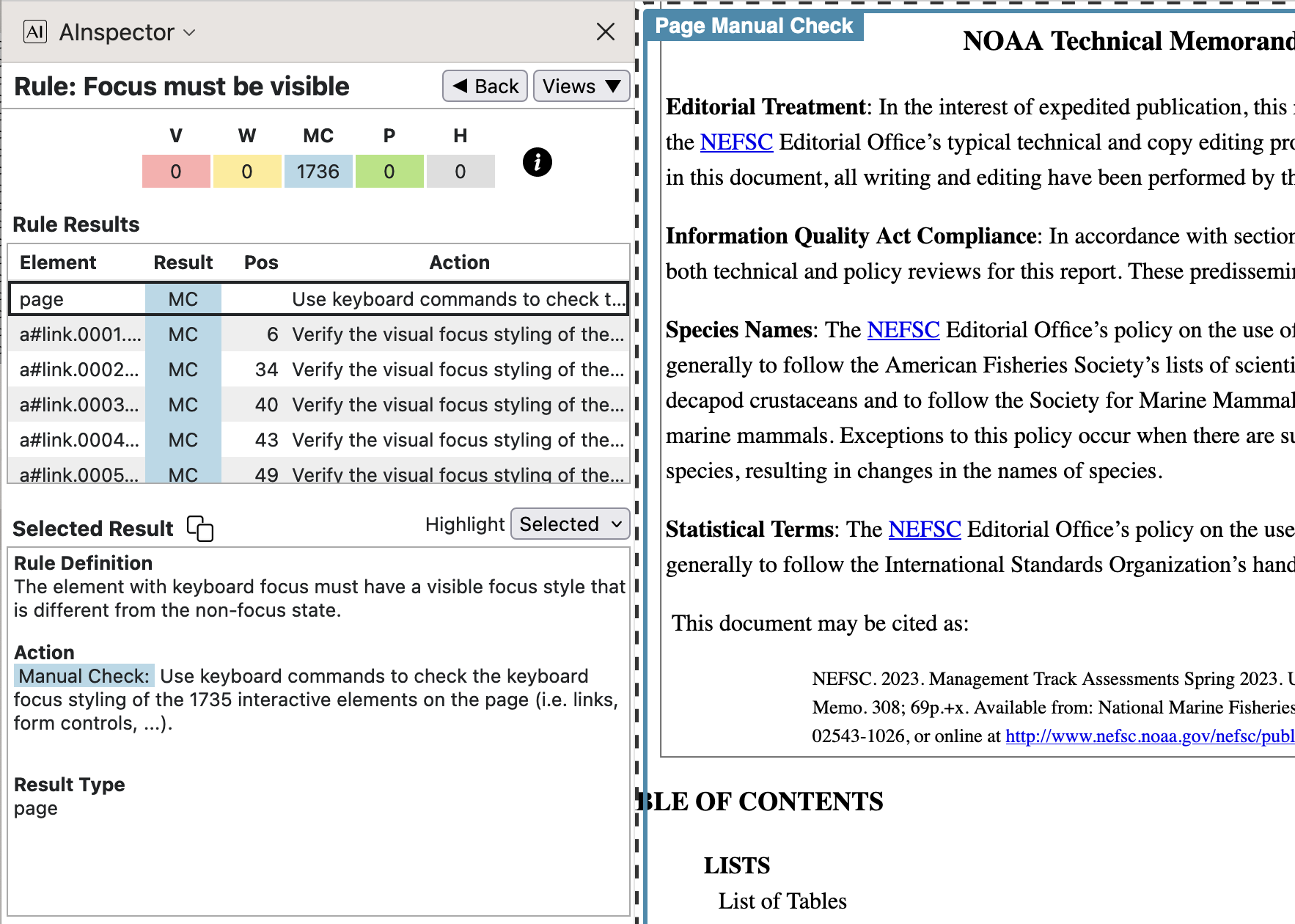
Here the issue is about whether the browser software shows a visible border around a link or other selected (interactive) element to indicate focus on that element. With Firefox there is a ‘Preference’ item that needs to be activated; then this does occur.
Firefox Chrome Acrobat 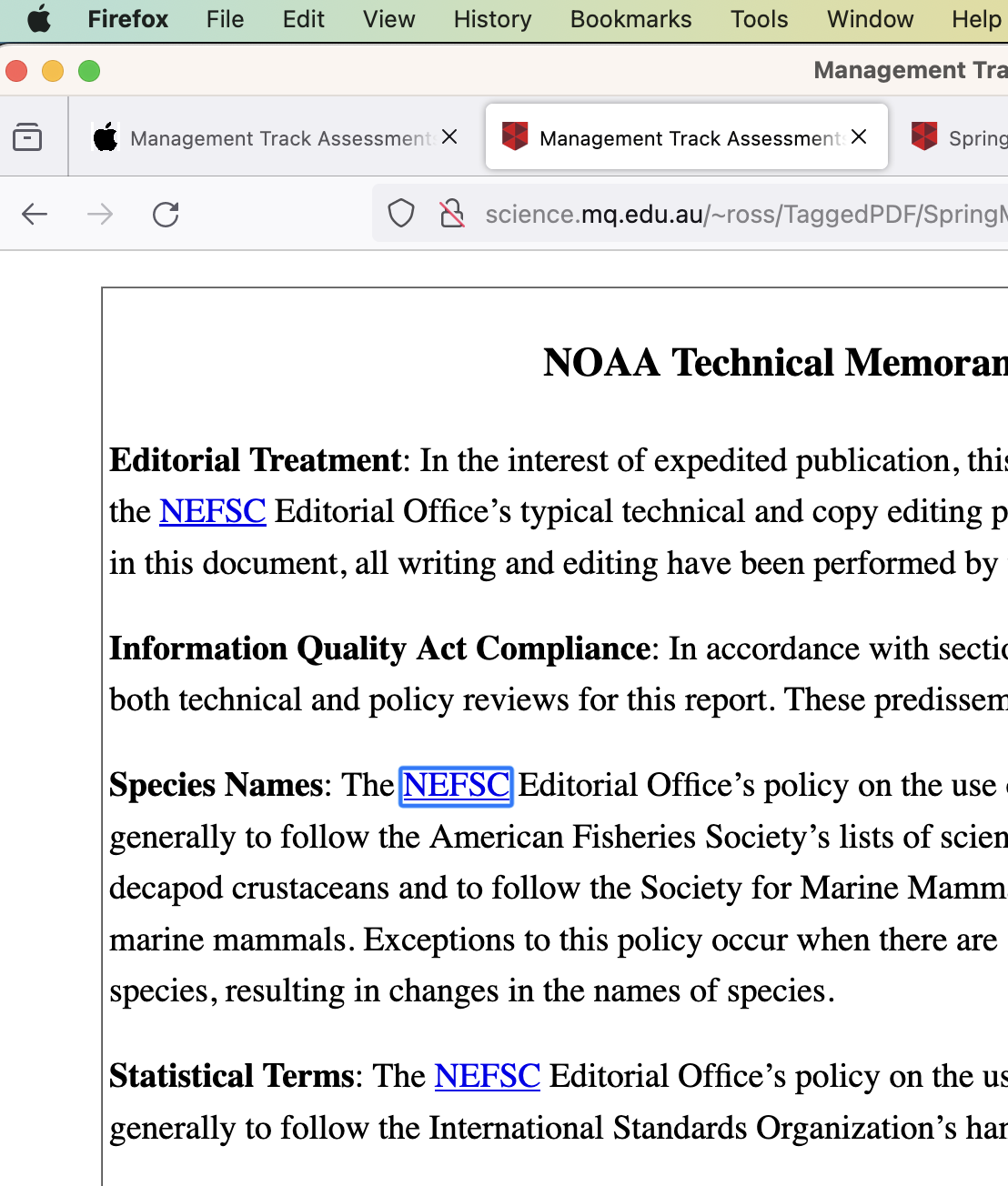
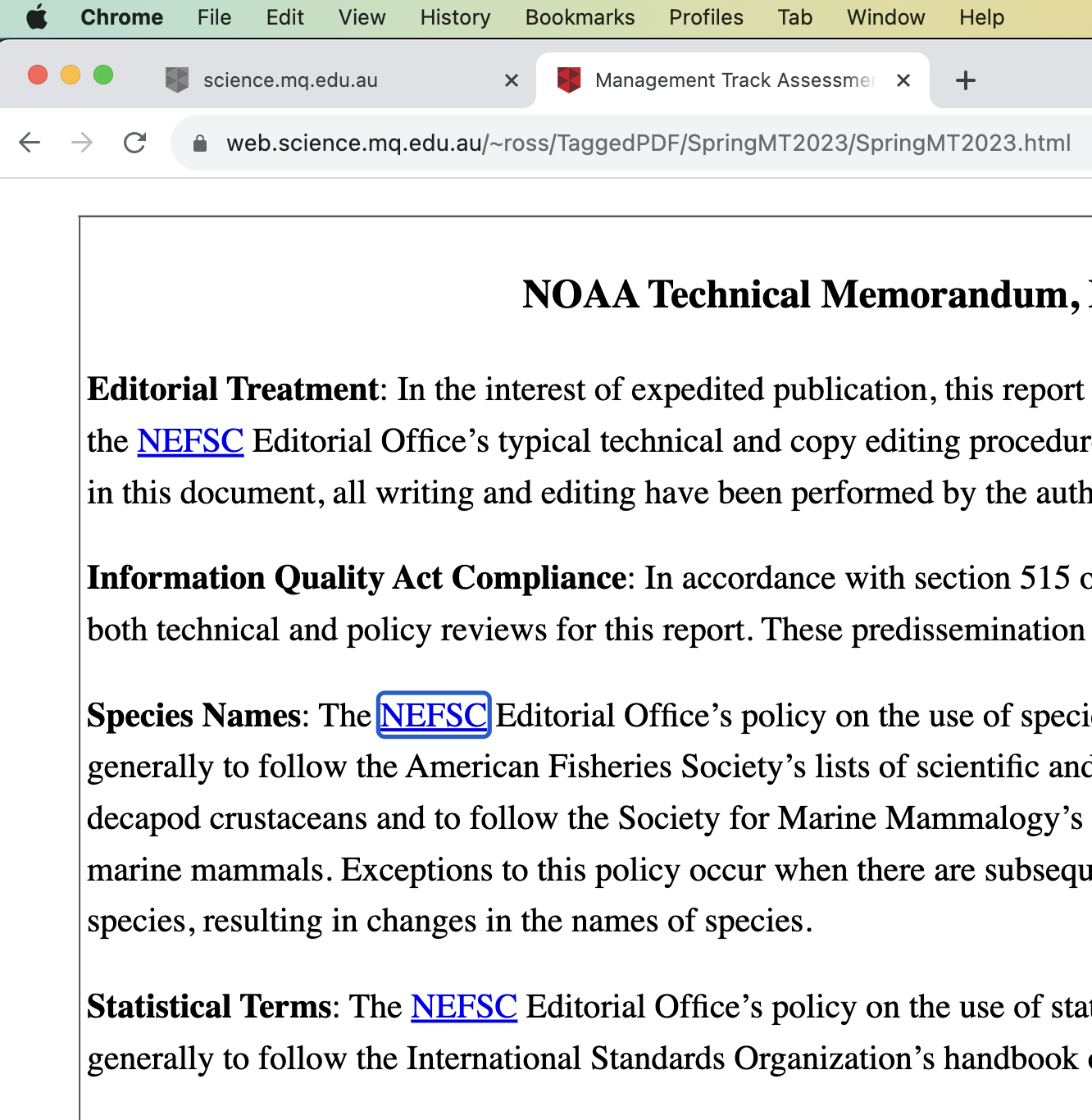
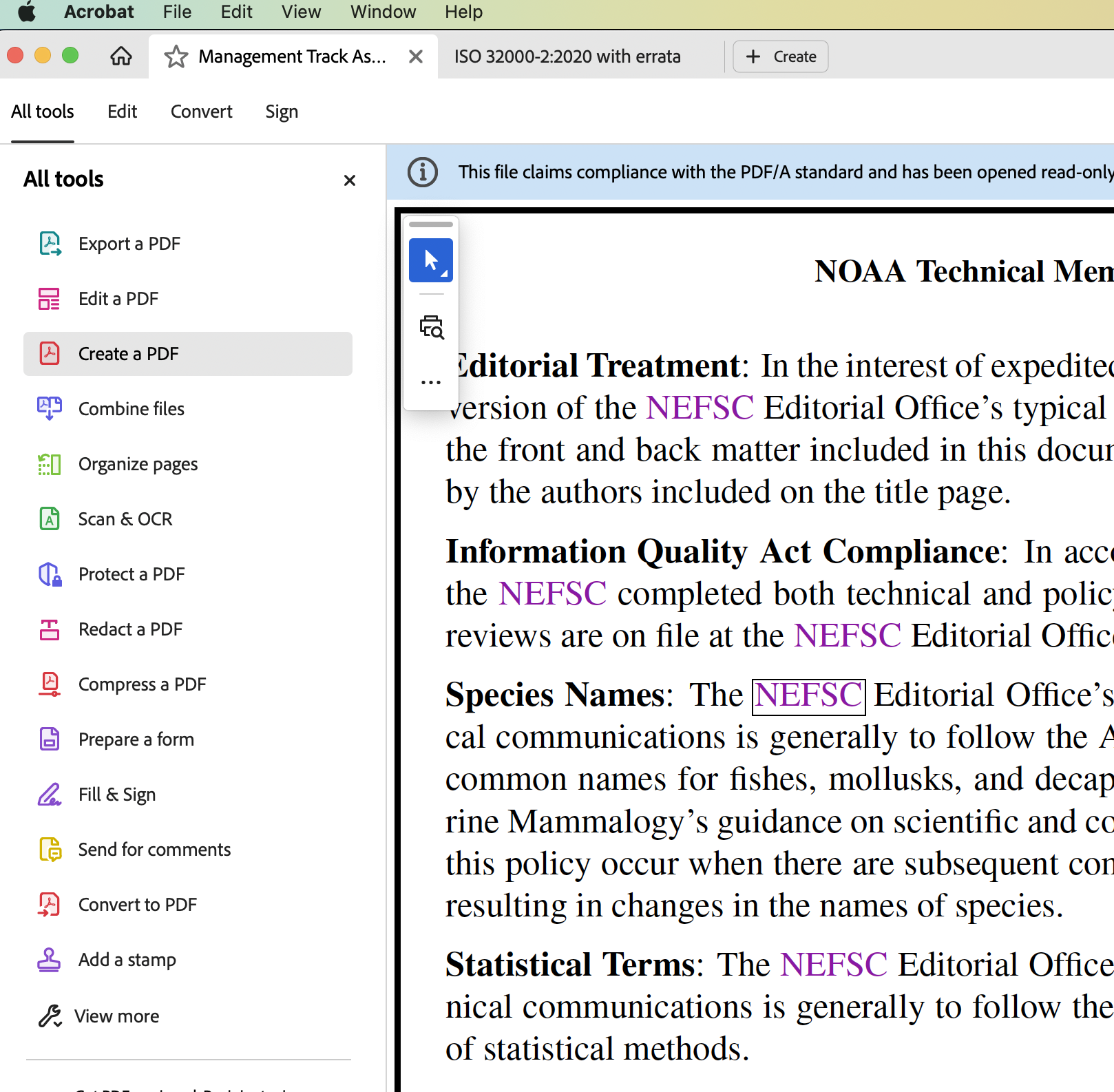
- Table of Contents, link to sectioning, starting on a particular page.
Observe the rectangles around the link for ‘NEFSC’ following ‘Species Names:’, as obtained using tabbing in 3 browsers; 2 for HTML, 1 for PDF. Each browser has ‘Preference’ settings to adjust the style of these rectangles.
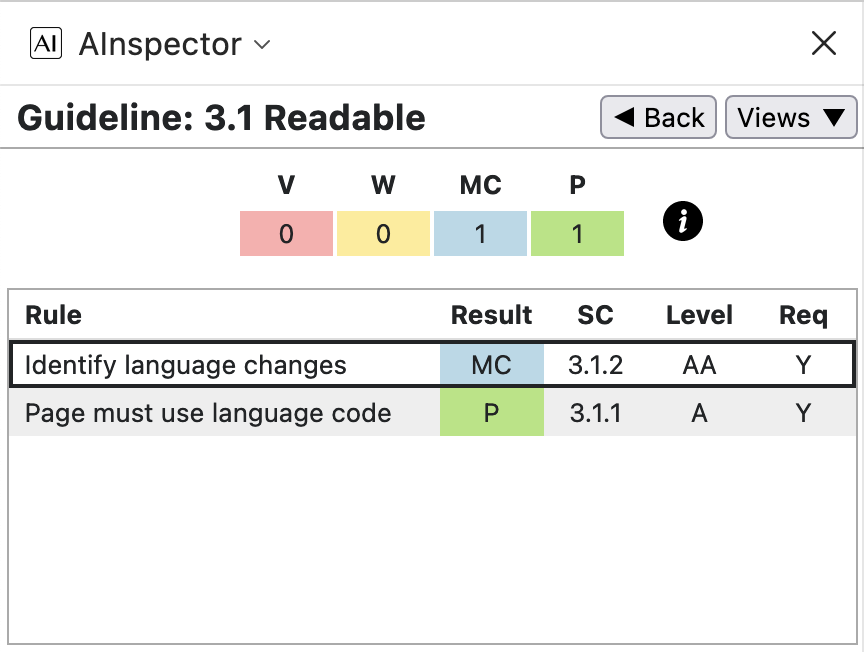
WCAG Guideline 3.1: Readable
- 3.1.2 ‘Identify language changes’
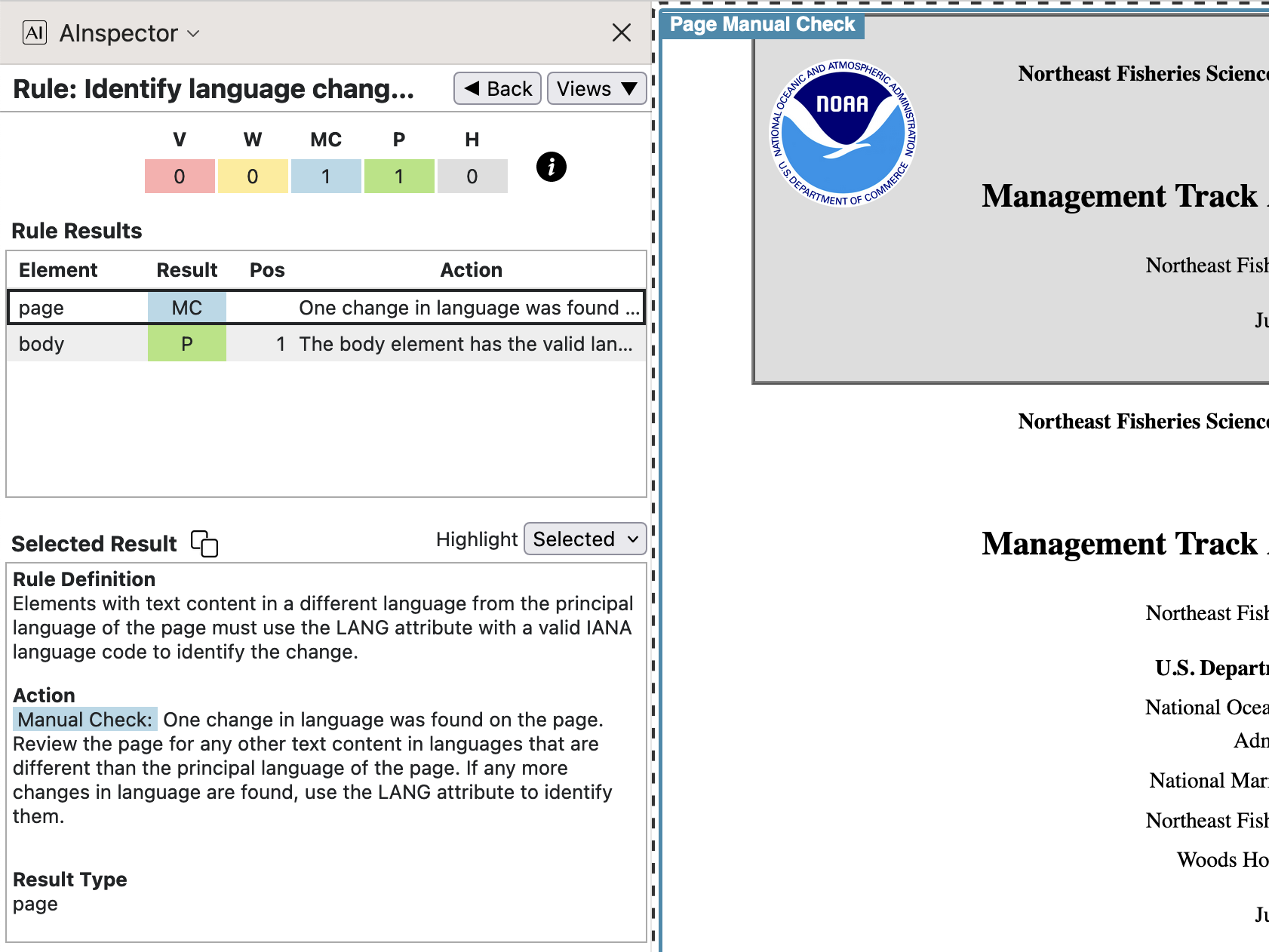
The default language is set on the <html> tag, and again with <body lang="en-us">.
Note that the PDF specifies /Lang (en-US), whereas the Country Code is given in lowercase in the HTML.
This may be technically an error in the ngPDF derivation software, though not likely to lead to any misunderstanding.
WCAG Guideline 4.1: Compatible
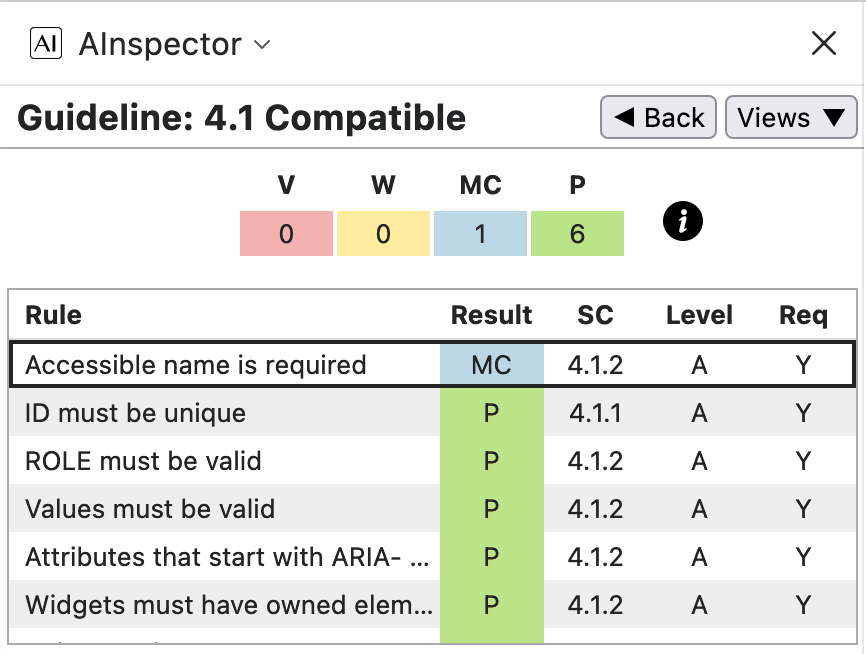
- 4.1.2 ‘Accessible name is required’, and Pass tests
The MCs here should arise only when
<tr>occur as part of interactive grid structures; but here they occur within static tables. This is due to a mistake in the AInspector software, related to the issue discussed above under SC 3.3.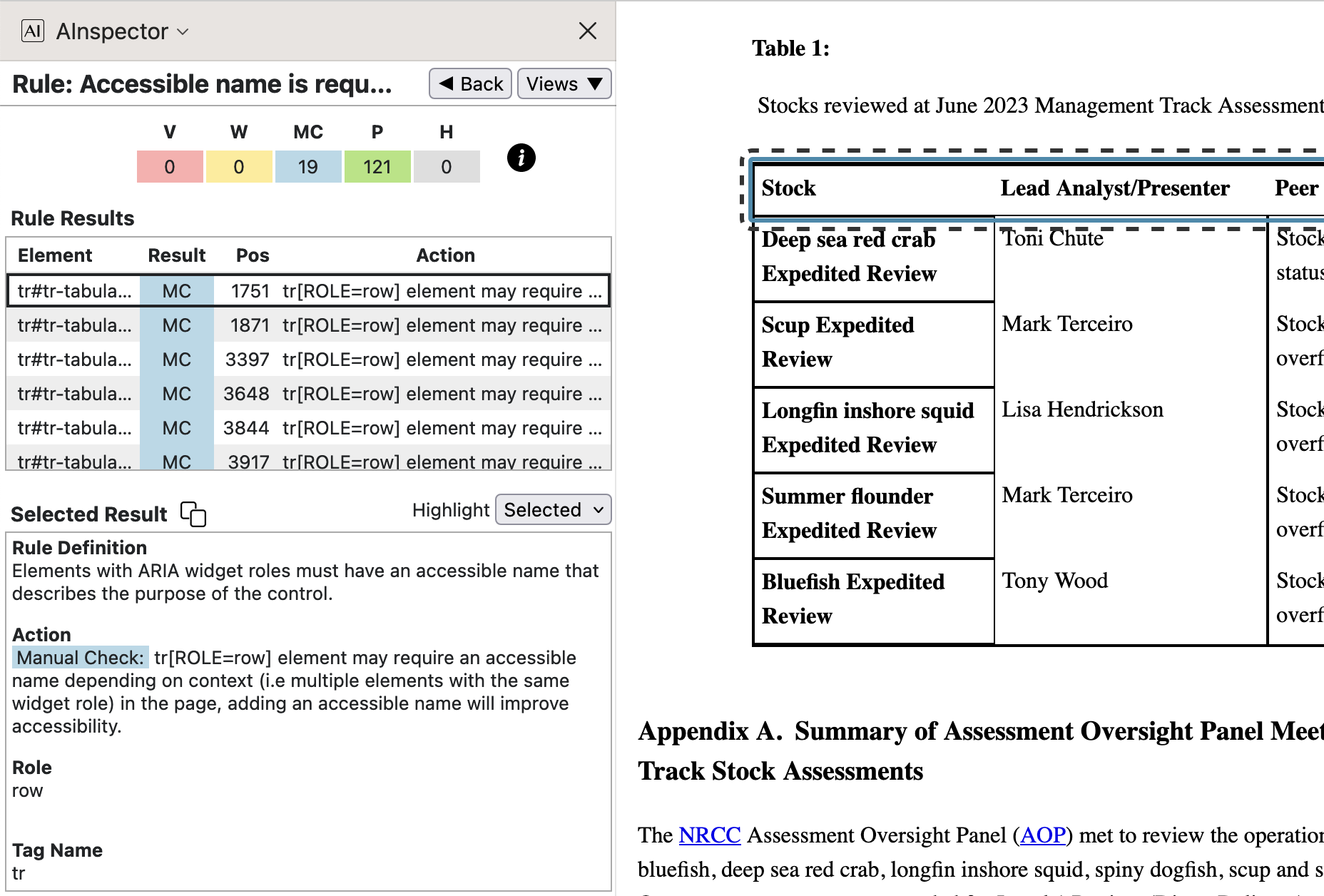
There is no sensible name to apply to the top row of the table, as shown. This is the same for the 19 rows reported, occuring in other tabular structures. On the other hand, the lower rows are part of the 121 Passing elements, where the 1st column is a header for cells on the same row. The ‘Accessible Name’ for these rows is (perhaps unnecessarily) built from the contents of that 1st cell.